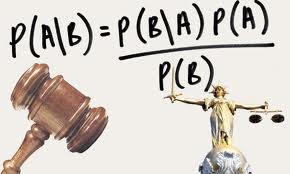 In machine learning, classification is the process of identifying the category of an unknown input based on the set of categories we already have. A classifier, as the name suggests, classifies things into multiple categories. It is used in various real life situations like face detection, image search, fingerprint recognition, etc. Some of the tasks are really simple and a machine can identify the class with absolute certainty. A common example would be to determine if a given number is even or odd. Pretty simple right! But most of the real life problems are not this simple and there is absolutely no way a machine can identify it with absolute certainty. For example, object recognition, weather prediction, handwriting analysis etc. So how do machines deal with these problems? What approach can be used here?
In machine learning, classification is the process of identifying the category of an unknown input based on the set of categories we already have. A classifier, as the name suggests, classifies things into multiple categories. It is used in various real life situations like face detection, image search, fingerprint recognition, etc. Some of the tasks are really simple and a machine can identify the class with absolute certainty. A common example would be to determine if a given number is even or odd. Pretty simple right! But most of the real life problems are not this simple and there is absolutely no way a machine can identify it with absolute certainty. For example, object recognition, weather prediction, handwriting analysis etc. So how do machines deal with these problems? What approach can be used here?
How do we deal with uncertainties?
When we cannot determine the outcome of an event with absolute certainty, we rely on probabilistic classification. Algorithms of this nature use probabilities to find the best category for a given input. Unlike other algorithms, which simply output the best class, probabilistic algorithms output probabilities of the input being a member of all the possible categories. The best one is normally then selected as the one with the highest probability.
It’s not always completely uncertain
Let A and B be two events. The term “events” doesn’t have any special meaning here. An event can be as general as “it will rain tomorrow” or “the flight will be delayed by more than an hour”. Even though we cannot predict the outcome of these events with absolute certainty, we can definitely get a good estimate. Now Bayes’ law says that the probability of occurrence of an event changes if there is information available about a related event. For example, if I ask you what’s the probability that it will rain tomorrow, an unbiased answer would be that there is a 50% chance. It will either rain or not rain! Now if I tell you that it has rained every single day in the last two weeks, will you change your answer? Most certainly. Bayes’ theorem gives us a way to account for the evidence available and update our model.
What is a Bayesian Classifier?
Based on Bayes’ theorem, many classifiers have been designed. A classifier is an algorithm or a formulation that classifies the input into one of the known categories. A practical example would be face recognition. The system is supposed to recognize the face and identify who that person is. This classification process is performed by a classifier (not necessarily a Bayesian classifier). Now the idea behind a Bayesian classifier is that if a model knows the category, it can predict the values of the other features. If it does not know the category, Bayes’ rule can be used to predict the class given the face that we know other feature values. In a Bayesian classifier, the learning agent builds a probabilistic model of the features and uses that model to predict the classification of a new unknown input. A learning agent can be an algorithm, a formulation or simply a paradigm that analyzes the patterns and learns from it.
A Simple Bayesian Classifier
The simplest case of a Bayesian Classifier is the Naive Bayesian classifier, which makes the independence assumption. This assumption says that that the input features are conditionally independent of each other. This means that the input features don’t depend on each other and that the occurrence of a feature doesn’t affect the occurrence of any other feature. To demonstrate this, let’s consider an example. From a deck of cards, you take out a card and put it back. Then you pick out a card again, and put it back. Now the chances that the first card is greater than 7 and the second card being an even number are totally independent. The outcomes of those two events don’t depend on each other. On the other hand, the chances that the first card is greater than 7 and the sum of the two cards is greater than 10 are dependent on each other. Once you get 7 on the first card, there is definitely a higher chance that the sum will be greater than 10. These two events are not independent. This is a very important concept in pattern recognition and machine learning.
In many real life situations, this is not the case. The occurrence of most of the features depends on the occurrence of other features. But computing the correlation between the features is difficult and time consuming. Hence Naive Bayes Classifier assumes that the input features are independent of each other and computes the probability of an unknown input belonging to a particular category. The one with the highest probability will be assigned to that input. To learn a classifier, the distributions for each input feature can be learned from the data. Despite these simplifying assumptions, Naive Bayes gives results as good or better than much more sophisticated approaches.
————————————————————————————————-

One thought on “Bayesian Classifier”