 Out of the three acronyms in the title, I guess you are most familiar with URL. Some of you may have heard the other two being thrown around here and there. These acronyms are basically related to the internet. To be specific, they are related to accessing stuff on the internet. What is the purpose of having those three acronyms in the first place? What is the difference between them? Why does it matter? This may be confusing to some, so I thought I should share my understanding of the these concepts.
Out of the three acronyms in the title, I guess you are most familiar with URL. Some of you may have heard the other two being thrown around here and there. These acronyms are basically related to the internet. To be specific, they are related to accessing stuff on the internet. What is the purpose of having those three acronyms in the first place? What is the difference between them? Why does it matter? This may be confusing to some, so I thought I should share my understanding of the these concepts.
URI
Before jumping into URL, we need to understand what URI means. URI stands for Uniform Resource Identifier and it identifies a resource either by location, or a name, or both. Now what do we mean by “resource”? A resource, or a web resource in our case, refers to anything ranging from documents, files, images, web pages, etc that can be part of the web architecture. When you open your browser to look at something, you are actually looking up a bunch of web resources. More often than not, we use URIs that define the location of a resource. The fact that a URI can identify resources by both name and location has lead to a lot of the confusion. A URI has two specializations: one is URN and the other is URL.
 A URI does not have to specify the location of a specific representation. For example, W3C use the following URI for their homepage: http://www.w3.org/Icons/w3c_home. Note that there is no file extension. If you didn’t already know, W3C stands for World Wide Web Consortium and they are the people who maintain the world wide web i.e. they govern the internet. The URI for the w3c_home image is still universally unique, but it does not specify the specific representation of the image (either a JPG, PNG, or GIF). The selection of the representation can be determined by the web server through HTTP content negotiation.
A URI does not have to specify the location of a specific representation. For example, W3C use the following URI for their homepage: http://www.w3.org/Icons/w3c_home. Note that there is no file extension. If you didn’t already know, W3C stands for World Wide Web Consortium and they are the people who maintain the world wide web i.e. they govern the internet. The URI for the w3c_home image is still universally unique, but it does not specify the specific representation of the image (either a JPG, PNG, or GIF). The selection of the representation can be determined by the web server through HTTP content negotiation.
Wait a minute, now what is content negotiation? It is a mechanism for serving different versions of a file at the same URI. The reason being not all devices can open the same format of a file. For example, the same image can be encoded in PNG, JPG and GIF. Depending on the device, you can serve the appropriate image. This way, the user doesn’t have to worry about going to a different URI. Oddly enough, only a few sites take advantage of HTTP content negotiation. The W3C is one web application that makes heavy use of URIs and content negotiation.
URN
URN stands for Uniform Resource Name and it identifies a resource by name in a given namespace. A namespace refers a group of names or identifiers. A simple real-life example would be the usage of our last names. If you just try to identify somebody with their first names, it may not be unique. But if you use their last name along with their first name, you can identify them easily. The last name is the namespace and the first name is the identifier.
One issue with URN is that it does not define how the resource may be obtained. You may see URNs used in XML Schema documents to define a namespace, usually using a syntax such as:
<xsd:schema xmlns="http://www.w3.org/2001/XMLSchema"
xmlns:xsd="http://www.w3.org/2001/XMLSchema"
targetNamespace="urn:example"
Here the “targetNamespace” uses a URN. It defines an identifier to the namespace, but it does not define a location. We can use any name to be a URN. For example, John Smith could be used like a URN. But these are actually much more regulated and intended to be unique across both space and time.
In our example earlier, since John Smith is a very common name, it’s not globally unique and would not be appropriate as a URN. However, even if no other family used this last name, it still wouldn’t be unique across time because somebody else in your family might be named John. URNs are different from URLs in this rigid uniqueness constraint, even though they both share the syntax of URIs.
URL
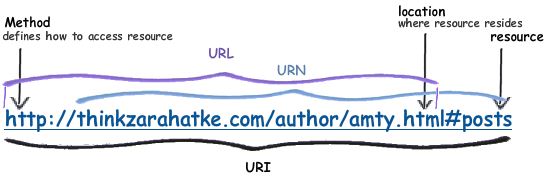
URL stands for Uniform Resource Locator and it is a specialization of URI that defines the network location of a specific resource. Unlike a URN, the URL defines how the resource can be obtained. We use URLs every day in the form of http://mywebsite.com, etc. But a URL doesn’t have to be an HTTP URL, it can be ftp://mywebsite.com, smb://mywebsite.com, etc.
All URLs are URIs, but not all URIs are URLs. A URL is a specialization of URI that defines the location of a specific representation for a given resource. Taking the same W3C example, there are actually 2 representations available for the w3c_home resource:
http://www.w3.org/Icons/w3c_home.gif http://www.w3.org/Icons/w3c_home.png
These URIs also define the file extension that indicates what content type is available at the URL. Through content negotiation, when the URI http://www.w3.org/Icons/w3c_home is accessed, the web server will forward the user agent to the proper type depending on the client’s capabilities. If we are being technical, URI is the correct term to use when referring to the location of resources on the web.
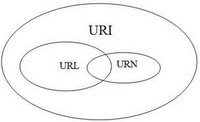
A URI is an identifier for some resource, but a URL gives you specific information as to how we can obtain that resource. Generally, if the URL describes both the location and name of a resource, the term to use is URI. URIs identify and URLs locate; however, locations are also identifications, so every URL is also a URI, but there are URIs which are not URLs. The figure below should make things clearer:
We can see how URL and URN are part of URI.
Everything Is Better With An Example
Let’s consider the example of John Smith. Since that is his name, that would be his identification. It is like a URI, but it cannot be a URL, because it tells you nothing about the location of John Smith or how to contact him. In this case, it also happens to identify at least a few other people named John Smith in the US alone. Now if we have something like “532 Mary Avenue, Atlanta, USA”. This is a location, which is the identification for that physical location. It is like both a URL and URI (since all URLs are URIs), and also identifies John Smith indirectly as the resident of that address. In this case, it uniquely identifies him. Of course that that would change if he gets a roommate.
————————————————————————————————-

Nice Explanation… Its clear now
Thanks.
Thanks
cool… its really nice article explains about URI (URL || URN).
Thanks to the author….
This is the very interesting article and it helped me to learn a lot. So, I wrote an article today. It’s all about the URLs, URL meaning, URI vs URN, URI vs URL bs URN and URL meaning please check and let me know if its interesting.
This is the very interesting article and it helped me to learn a lot. So, I wrote an article today. It’s all about the URLs, URL meaning, URI vs URN, URI vs URL bs URN and URL meaning please check and let me know if its interesting.
For Clearification You can read detalied article from this link related to
url vs uri
nice