 Probabilistic models are commonly used to model various forms of data, including physical, biological, seismic, etc. Much of their popularity can be attributed to the existence of efficient and robust procedures for learning parameters from observations. Often, however, the only data available for training a probabilistic model are incomplete. Missing values can occur which will not be sufficient to get the model. For example, in medical diagnosis, patient histories generally include results from a limited battery of tests. In gene expression clustering, incomplete data arise from the intentional omission of gene-to-cluster assignments in the probabilistic model. If we use regular techniques to estimate the underlying model, then we will get a wrong estimate. What do we do in these situations?
Probabilistic models are commonly used to model various forms of data, including physical, biological, seismic, etc. Much of their popularity can be attributed to the existence of efficient and robust procedures for learning parameters from observations. Often, however, the only data available for training a probabilistic model are incomplete. Missing values can occur which will not be sufficient to get the model. For example, in medical diagnosis, patient histories generally include results from a limited battery of tests. In gene expression clustering, incomplete data arise from the intentional omission of gene-to-cluster assignments in the probabilistic model. If we use regular techniques to estimate the underlying model, then we will get a wrong estimate. What do we do in these situations?
What is expectation-maximization?
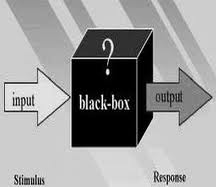 Let’s say you want to mix two colors of paints (red and blue) and obtain a new color using a machine. Now the problem is that this machine is a black box and you don’t know what it does. All you know if that it is capable of mixing two colors in some way. It may mix them in different proportions or it may add a third color or it may just may equally dilute them. Now your job is to find out what it does exactly. So you put in some amount of paint of each color into the box and see what comes out. Now you have a rough idea of how far you are from the resultant color you want. You will change the proportion of red and blue so that the output is a bit closer to what you want. You will continue this until you get the final color.
Let’s say you want to mix two colors of paints (red and blue) and obtain a new color using a machine. Now the problem is that this machine is a black box and you don’t know what it does. All you know if that it is capable of mixing two colors in some way. It may mix them in different proportions or it may add a third color or it may just may equally dilute them. Now your job is to find out what it does exactly. So you put in some amount of paint of each color into the box and see what comes out. Now you have a rough idea of how far you are from the resultant color you want. You will change the proportion of red and blue so that the output is a bit closer to what you want. You will continue this until you get the final color.
In machine learning and pattern recognition, we frequently encounter these “black boxes”. Hence we rely on expectation-maximization (EM) to estimate the underlying model. The EM algorithm alternates between the steps of guessing a probability distribution over completions of missing data given the current model (known as the E-step) and then re-estimating the model parameters using these completions (known as the M-step). E-step corresponds to putting the colored paints into the black box and M-step corresponds to what you did in the following cycle after looking at the output. The name ‘E-step’ comes from the fact that one does not usually need to form the probability distribution over completions explicitly. We just need to compute ‘expected’ sufficient statistics over these completions. Similarly, the name ‘M-step’ comes from the fact that model reestimation can be thought of as ‘maximization’ of the expected value of the data.
Why is it even necessary?
If all the data is available, then we use something called “maximum likelihood estimation” to determine the underlying distribution. The EM algorithm is a natural generalization of maximum likelihood estimation to the incomplete data case. In particular, EM attempts to find the parameters that maximize the expectation of the observed data. It means that it will try to find the parameters for the model which will maximize the chances that our guess was indeed correct. Generally speaking, the optimization problem addressed by the expectation-maximization algorithm is more difficult than the optimization used in maximum likelihood estimation. In the complete data case, the objective function has a single global optimum, which can often be found in closed form. In contrast, in the incomplete data case the objective function has multiple local maxima and no closed form solution.
Where is it used?
EM algorithm is frequently used in machine learning and computer vision. It is used in natural language processing as well (the famous Baum-Welch algorithm is an example for this). Many probabilistic models in computational biology include latent variables. In some cases, these latent variables are present due to missing or corrupted data. In most applications of expectation-maximization to computational biology, however, the latent factors are intentionally included, and parameter learning itself provides a mechanism for knowledge discovery. EM is also used in medical image reconstruction, gene expression clustering, motif finding, haplotype inference problem etc.
 In each case, expectation maximization provides a simple, easy-to-implement and efficient tool for learning parameters of a model. Once these parameters are known, we can use probabilistic inference to ask interesting queries about the model. For example, what cluster does a particular gene most likely belong to? What is the most likely starting location of a motif in a particular sequence? What are the most likely haplotype blocks making up the genotype of a specific individual? By providing a straightforward mechanism for parameter learning in all of these models, expectation maximization provides a mechanism for building and training rich probabilistic models for biological applications.
In each case, expectation maximization provides a simple, easy-to-implement and efficient tool for learning parameters of a model. Once these parameters are known, we can use probabilistic inference to ask interesting queries about the model. For example, what cluster does a particular gene most likely belong to? What is the most likely starting location of a motif in a particular sequence? What are the most likely haplotype blocks making up the genotype of a specific individual? By providing a straightforward mechanism for parameter learning in all of these models, expectation maximization provides a mechanism for building and training rich probabilistic models for biological applications.
————————————————————————————————-

You can see it in action on the github project:
https://github.com/juandavm/em4gmm
It’s a real implementation of the EM for Gaussian Mixtures 😀
Good article!!!
Thanks for the link 🙂