 Even though it has an ornate name, the underlying concept is actually quite simple and intuitive. The concept of Empirical Risk Minimization becomes relevant in the world of supervised learning. The actual goal of supervised learning is to find a model that solves a problem as opposed to finding a model that best fits the given dataset. Since we don’t have every single data point that represents each class completely, we just use the next best thing available, which is a dataset that’s representative of the classes. We can think of the process of supervised learning as choosing a function that achieves a given goal. We have to choose this function from a set of potential functions. Now how can we measure the effectiveness of this chosen function given that we don’t know what the actual distribution looks like? Bear in mind that all the potential functions can achieve the given goal. How do we find the function that’s the best representative of the true solution? Continue reading “What is Empirical Risk Minimization”
Even though it has an ornate name, the underlying concept is actually quite simple and intuitive. The concept of Empirical Risk Minimization becomes relevant in the world of supervised learning. The actual goal of supervised learning is to find a model that solves a problem as opposed to finding a model that best fits the given dataset. Since we don’t have every single data point that represents each class completely, we just use the next best thing available, which is a dataset that’s representative of the classes. We can think of the process of supervised learning as choosing a function that achieves a given goal. We have to choose this function from a set of potential functions. Now how can we measure the effectiveness of this chosen function given that we don’t know what the actual distribution looks like? Bear in mind that all the potential functions can achieve the given goal. How do we find the function that’s the best representative of the true solution? Continue reading “What is Empirical Risk Minimization”
Tag: Distribution
What Is Pareto Optimality
 Let’s consider a business deal where there are multiple parties negotiating the terms. In such a situation, it’s usually not possible for every single party to get everything it wants. They need to optimize their demands so that everyone comes out with something positive. Similar situations arise across many areas of engineering where we have to deal with many resources and we need to make a trade off based on cost, quality, speed, and so on. How do we model this problem and decide the optimal state of affairs? This is where the concept of Pareto Optimality comes into picture. Continue reading “What Is Pareto Optimality”
Let’s consider a business deal where there are multiple parties negotiating the terms. In such a situation, it’s usually not possible for every single party to get everything it wants. They need to optimize their demands so that everyone comes out with something positive. Similar situations arise across many areas of engineering where we have to deal with many resources and we need to make a trade off based on cost, quality, speed, and so on. How do we model this problem and decide the optimal state of affairs? This is where the concept of Pareto Optimality comes into picture. Continue reading “What Is Pareto Optimality”
What Is Relative Entropy?
 In this blog post, we will be using a bit of background from my previous blog post. If you are familiar with the basics of entropy coding, you should be fine. If not, you may want to quickly read through my previous blog post. So coming to the topic at hand, let’s continue our discussion on entropy coding. Let’s say we have a stream of English alphabets coming in, and you want to store them in the best possible way by consuming the least amount of space. So you go ahead and build your nifty entropy coder to take care of all this. But what if you don’t have access to all the data? How do you know what alphabet appears most frequently if you can’t access the full data? The problem now is that you cannot know for sure if you have chosen the best possible representation. Since you cannot wait forever, you just wait for the first ‘n’ alphabets and build your entropy coder hoping that the rest of the data will adhere to this distribution. Do we end up suffering in terms of compression by doing this? How do we measure the loss in quality? Continue reading “What Is Relative Entropy?”
In this blog post, we will be using a bit of background from my previous blog post. If you are familiar with the basics of entropy coding, you should be fine. If not, you may want to quickly read through my previous blog post. So coming to the topic at hand, let’s continue our discussion on entropy coding. Let’s say we have a stream of English alphabets coming in, and you want to store them in the best possible way by consuming the least amount of space. So you go ahead and build your nifty entropy coder to take care of all this. But what if you don’t have access to all the data? How do you know what alphabet appears most frequently if you can’t access the full data? The problem now is that you cannot know for sure if you have chosen the best possible representation. Since you cannot wait forever, you just wait for the first ‘n’ alphabets and build your entropy coder hoping that the rest of the data will adhere to this distribution. Do we end up suffering in terms of compression by doing this? How do we measure the loss in quality? Continue reading “What Is Relative Entropy?”
What Is Entropy Coding?
 Entropy Coding appears everywhere in modern digital systems. It is a fundamental building block of data compression, and data compression is pretty much needed everywhere, especially for internet, video, audio, communication, etc. Let’s consider the following scenario. You have a stream of English alphabets coming in and you want to store them in the best possible way by consuming the least amount of space. For the sake of discussion, let’s assume that they are all uppercase letters. Bear in mind that you have an empty machine which doesn’t know anything, and it understands only binary symbols i.e. 0 and 1. It will do exactly what you tell it to do, and it will need data in binary format. So what do we do here? One way would be to use numbers to represent these alphabets, right? Since there are 26 alphabets in English, we can convert them to numbers ranging from 0 to 25, and then convert those numbers into binary form. The biggest number, 25, needs 5 bits to be represented in binary form. So considering the worst case scenario, we can say that we need 5 bits to represent every alphabet. If have to store 100 alphabets, we will need 500 bits. But is that the best we can do? Are we perhaps not exploring our data to the fullest possible extent? Continue reading “What Is Entropy Coding?”
Entropy Coding appears everywhere in modern digital systems. It is a fundamental building block of data compression, and data compression is pretty much needed everywhere, especially for internet, video, audio, communication, etc. Let’s consider the following scenario. You have a stream of English alphabets coming in and you want to store them in the best possible way by consuming the least amount of space. For the sake of discussion, let’s assume that they are all uppercase letters. Bear in mind that you have an empty machine which doesn’t know anything, and it understands only binary symbols i.e. 0 and 1. It will do exactly what you tell it to do, and it will need data in binary format. So what do we do here? One way would be to use numbers to represent these alphabets, right? Since there are 26 alphabets in English, we can convert them to numbers ranging from 0 to 25, and then convert those numbers into binary form. The biggest number, 25, needs 5 bits to be represented in binary form. So considering the worst case scenario, we can say that we need 5 bits to represent every alphabet. If have to store 100 alphabets, we will need 500 bits. But is that the best we can do? Are we perhaps not exploring our data to the fullest possible extent? Continue reading “What Is Entropy Coding?”
What Are Confidence Intervals?
 Confidence interval is a concept in statistics that is used extensively in many diverse areas like physics, chemistry, computer vision, machine learning, genetics, etc. This concept is so fundamental that any modern science would eventually end up using it. Let’s say you have collected some data and you want to understand the behavior of that data. For example, you can say that the data is centered around some value or that the data is distributed with a certain amount of variance. This is very common in many fields where you have estimate the underlying parameters that govern the data distribution. When you estimate a statistical parameter from some data, you can’t be certain about its true value. If you have a lot of high-quality data, then you’re more confident that your estimate is near its true value. But if you don’t have a lot of data, or if it’s of poor quality, then you don’t have much confidence in it. So how do we deal with these situations? Can we measure this uncertainty? Continue reading “What Are Confidence Intervals?”
Confidence interval is a concept in statistics that is used extensively in many diverse areas like physics, chemistry, computer vision, machine learning, genetics, etc. This concept is so fundamental that any modern science would eventually end up using it. Let’s say you have collected some data and you want to understand the behavior of that data. For example, you can say that the data is centered around some value or that the data is distributed with a certain amount of variance. This is very common in many fields where you have estimate the underlying parameters that govern the data distribution. When you estimate a statistical parameter from some data, you can’t be certain about its true value. If you have a lot of high-quality data, then you’re more confident that your estimate is near its true value. But if you don’t have a lot of data, or if it’s of poor quality, then you don’t have much confidence in it. So how do we deal with these situations? Can we measure this uncertainty? Continue reading “What Are Confidence Intervals?”
What Are P-Values?
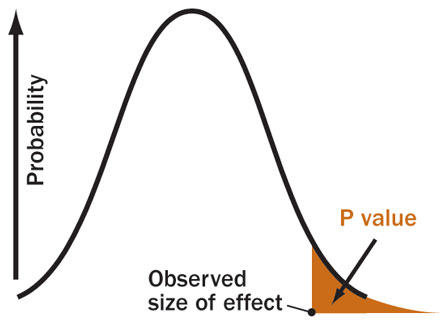 Let’s say you are a part of the sub-atomic physics team and you are working on discovering an important effect. The thing about sub-atomic physics is that nothing is certain and you cannot say something has happened with 100% certainty. The best we can do is to say that we are x-percent sure that something interesting happened. One fine day, you see some pattern in your data which looks pretty much like what that effect would look like. Now the problem is, your experiment produced data with a lot of noise. People are therefore skeptical of you, and think that the supposed “effect” you claimed to see might just have been a funny pattern in some random noise. How would you convince them that it’s not? Before that, how do you convince yourself that it’s not just noise? A good strategy for arguing your point would be to say, “Alright listen, suppose you’re right, and the patterns in my data really are in fact just from random noise, then how would you explain the fact that random noise very rarely produces patterns like this?”. Pretty good strategy right? Now how do we formulate this mathematically? Continue reading “What Are P-Values?”
Let’s say you are a part of the sub-atomic physics team and you are working on discovering an important effect. The thing about sub-atomic physics is that nothing is certain and you cannot say something has happened with 100% certainty. The best we can do is to say that we are x-percent sure that something interesting happened. One fine day, you see some pattern in your data which looks pretty much like what that effect would look like. Now the problem is, your experiment produced data with a lot of noise. People are therefore skeptical of you, and think that the supposed “effect” you claimed to see might just have been a funny pattern in some random noise. How would you convince them that it’s not? Before that, how do you convince yourself that it’s not just noise? A good strategy for arguing your point would be to say, “Alright listen, suppose you’re right, and the patterns in my data really are in fact just from random noise, then how would you explain the fact that random noise very rarely produces patterns like this?”. Pretty good strategy right? Now how do we formulate this mathematically? Continue reading “What Are P-Values?”
Gaussian Mixture Models
 Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this? Continue reading “Gaussian Mixture Models”
Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this? Continue reading “Gaussian Mixture Models”
Expectation Maximization
 Probabilistic models are commonly used to model various forms of data, including physical, biological, seismic, etc. Much of their popularity can be attributed to the existence of efficient and robust procedures for learning parameters from observations. Often, however, the only data available for training a probabilistic model are incomplete. Missing values can occur which will not be sufficient to get the model. For example, in medical diagnosis, patient histories generally include results from a limited battery of tests. In gene expression clustering, incomplete data arise from the intentional omission of gene-to-cluster assignments in the probabilistic model. If we use regular techniques to estimate the underlying model, then we will get a wrong estimate. What do we do in these situations? Continue reading “Expectation Maximization”
Probabilistic models are commonly used to model various forms of data, including physical, biological, seismic, etc. Much of their popularity can be attributed to the existence of efficient and robust procedures for learning parameters from observations. Often, however, the only data available for training a probabilistic model are incomplete. Missing values can occur which will not be sufficient to get the model. For example, in medical diagnosis, patient histories generally include results from a limited battery of tests. In gene expression clustering, incomplete data arise from the intentional omission of gene-to-cluster assignments in the probabilistic model. If we use regular techniques to estimate the underlying model, then we will get a wrong estimate. What do we do in these situations? Continue reading “Expectation Maximization”
Reimann Hypothesis And Its Connection To Cryptography
 Over the centuries, mathematicians have been involved in solving some of most complex problems. But what is the motivation behind that? The pursuit of truth! But The Clay Mathematics Institute thought that there should be a little more than that. So to celebrate mathematics in the new millennium, they established seven Millennium Prize Problems. The prize money for each problem is one million dollars. That’s pretty exciting! These were some of the most difficult problems over which many mathematicians were racking their brains. Reimann Hypothesis is one of them. The interesting thing about this particular problem is that it has far reaching consequences in the field of modern cryptography and internet security. Now how can an obscure and complex mathematical problem affect cryptography and internet security? Continue reading “Reimann Hypothesis And Its Connection To Cryptography”
Over the centuries, mathematicians have been involved in solving some of most complex problems. But what is the motivation behind that? The pursuit of truth! But The Clay Mathematics Institute thought that there should be a little more than that. So to celebrate mathematics in the new millennium, they established seven Millennium Prize Problems. The prize money for each problem is one million dollars. That’s pretty exciting! These were some of the most difficult problems over which many mathematicians were racking their brains. Reimann Hypothesis is one of them. The interesting thing about this particular problem is that it has far reaching consequences in the field of modern cryptography and internet security. Now how can an obscure and complex mathematical problem affect cryptography and internet security? Continue reading “Reimann Hypothesis And Its Connection To Cryptography”
The Butterfly Effect
 This blog post is a continuation of my previous post on Chaos Theory. Although it is not required for you to read that post to understand this post, it would be better if you glance through it once. All of us have heard about the Butterfly Effect. It is one of the very famous examples given in the field of chaos theory. I should also give credit to the movie “The Butterfly Effect” for popularizing this term. So what exactly is butterfly effect? Is it just a theory? Where does it happen in real life? Continue reading “The Butterfly Effect”
This blog post is a continuation of my previous post on Chaos Theory. Although it is not required for you to read that post to understand this post, it would be better if you glance through it once. All of us have heard about the Butterfly Effect. It is one of the very famous examples given in the field of chaos theory. I should also give credit to the movie “The Butterfly Effect” for popularizing this term. So what exactly is butterfly effect? Is it just a theory? Where does it happen in real life? Continue reading “The Butterfly Effect”
