 Confidence interval is a concept in statistics that is used extensively in many diverse areas like physics, chemistry, computer vision, machine learning, genetics, etc. This concept is so fundamental that any modern science would eventually end up using it. Let’s say you have collected some data and you want to understand the behavior of that data. For example, you can say that the data is centered around some value or that the data is distributed with a certain amount of variance. This is very common in many fields where you have estimate the underlying parameters that govern the data distribution. When you estimate a statistical parameter from some data, you can’t be certain about its true value. If you have a lot of high-quality data, then you’re more confident that your estimate is near its true value. But if you don’t have a lot of data, or if it’s of poor quality, then you don’t have much confidence in it. So how do we deal with these situations? Can we measure this uncertainty?
Confidence interval is a concept in statistics that is used extensively in many diverse areas like physics, chemistry, computer vision, machine learning, genetics, etc. This concept is so fundamental that any modern science would eventually end up using it. Let’s say you have collected some data and you want to understand the behavior of that data. For example, you can say that the data is centered around some value or that the data is distributed with a certain amount of variance. This is very common in many fields where you have estimate the underlying parameters that govern the data distribution. When you estimate a statistical parameter from some data, you can’t be certain about its true value. If you have a lot of high-quality data, then you’re more confident that your estimate is near its true value. But if you don’t have a lot of data, or if it’s of poor quality, then you don’t have much confidence in it. So how do we deal with these situations? Can we measure this uncertainty?
Why do we need confidence interval?
 Whenever you collect data using some experiment, you see a bunch of instances. These are called observations and you try to infer the behavior of your data using these observations. Confidence intervals actually quantify these observations. Suppose that you have an experiment that produces some noisy data. It can happen in real life where you cannot really control everything in the experimental setup. To take a really simple example, let’s say your data has values ranging from 0 to 100 and you want to estimate the average. Remember that these values may not be true values because your experimental set up is very noisy. It is equivalent to the real value being 23 and you measuring it to be 25 because of your faulty setup. In an ideal situation, you would just sum up the numbers and divide it by the overall number of observations. But there’s no guarantee that it would be the real average because you don’t know what the real values are. Confidence interval provides a way to account for this.
Whenever you collect data using some experiment, you see a bunch of instances. These are called observations and you try to infer the behavior of your data using these observations. Confidence intervals actually quantify these observations. Suppose that you have an experiment that produces some noisy data. It can happen in real life where you cannot really control everything in the experimental setup. To take a really simple example, let’s say your data has values ranging from 0 to 100 and you want to estimate the average. Remember that these values may not be true values because your experimental set up is very noisy. It is equivalent to the real value being 23 and you measuring it to be 25 because of your faulty setup. In an ideal situation, you would just sum up the numbers and divide it by the overall number of observations. But there’s no guarantee that it would be the real average because you don’t know what the real values are. Confidence interval provides a way to account for this.
What exactly is a “confidence interval”?
A confidence interval is an interval which specifies the range for the parameter under consideration. In our earlier example, confidence interval specifies a range of values within which the average value will be present. We can say with 100% percent confidence that the average value with be between 0 and 100. So the range 0-100 is called 100% confidence interval. This information is not very useful, is it? I mean, we already know that the average value lies between 0 and 100. On the other hand, we can say with 40% confidence that the average value lies between 37.3 and 42.7. The range 37.3-42.7 is called 40% confidence interval. This information is not very useful either because the confidence value is so low. Ideally, we would like the range to be small and the confidence to be large. If we have that, then the information about confidence interval will be of some value. In practice, we require the confidence to be at least 95% for it to be considered for further analysis.
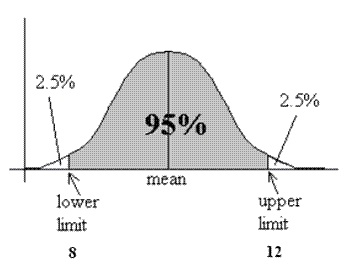 A confidence interval is an interval computed from your data, and is therefore random because the data is generated with randomness. The defining feature of a 95% confidence interval is that if you repeated the experiment many times, sampling new random data each time, then the computed 95% confidence interval would cover the true value of the parameter 95% of the time. So, if we have more data, confidence intervals get smaller. This means that the range gets tighter and we have a better estimate of the value of the parameter. If we have lower quality data, confidence intervals get larger. The range gets wider and there is more uncertainty.
A confidence interval is an interval computed from your data, and is therefore random because the data is generated with randomness. The defining feature of a 95% confidence interval is that if you repeated the experiment many times, sampling new random data each time, then the computed 95% confidence interval would cover the true value of the parameter 95% of the time. So, if we have more data, confidence intervals get smaller. This means that the range gets tighter and we have a better estimate of the value of the parameter. If we have lower quality data, confidence intervals get larger. The range gets wider and there is more uncertainty.
Where is it used?
 Confidence intervals are an effective and elegant solution to the problem of determining how confident you are in a parameter estimate. You might have seen them in the newspaper where they quoted the margin of sampling error of a poll. They’re also used far more widely in sciences too. Whenever we are performing experiments in physics, artificial intelligence, robotics, space science, etc, estimating the confidence interval is of utmost importance. Consider the example of a robot traveling on an unknown planet. If we are traversing an unknown terrain, we can never be completely certain about anything. The best we can do is evaluate the available paths and take the best one. Sometimes even the best path might lead to a disaster. So we need to evaluate the confidence level before we proceed.
Confidence intervals are an effective and elegant solution to the problem of determining how confident you are in a parameter estimate. You might have seen them in the newspaper where they quoted the margin of sampling error of a poll. They’re also used far more widely in sciences too. Whenever we are performing experiments in physics, artificial intelligence, robotics, space science, etc, estimating the confidence interval is of utmost importance. Consider the example of a robot traveling on an unknown planet. If we are traversing an unknown terrain, we can never be completely certain about anything. The best we can do is evaluate the available paths and take the best one. Sometimes even the best path might lead to a disaster. So we need to evaluate the confidence level before we proceed.
Considered as a random interval, the probability that the confidence interval contains the true parameter is 95%. But a subtle point to note is that once a confidence interval has actually been computed, giving you a fixed range like 37.3 to 42.7, you don’t actually know the probability that your parameter of interest is in that interval. It’s either there or it’s not there. That’s the reason why statisticians say that the parameter is in that interval with 95% confidence, rather than with 95% probability. Do you see the difference? It’s subtle, but important.
————————————————————————————————-
