 Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this?
Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this?
First of all, what is a mixture model?
Mixture Model is a type of density model which comprises of a number of component functions, usually Gaussian. These component functions are combined to provide a multimodal density. If you want to analyze different areas of Europe, it’s not sufficient to model it as one big continent. You need to understand what countries are inside Europe, where they are located, what their boundaries are, etc. You need to account for the multiple modes if you are trying to get a good representative model. Mixture Models can be employed to model the colors of an object in order to perform tasks such as real-time color-based tracking and segmentation. These tasks may be made more robust by generating a mixture model corresponding to background colors in addition to a foreground model, and employing a simple Bayesian classifier to perform pixel classification. Mixture models are also effective methods for online adaptation of models to cope with slowly-varying lighting conditions.
Mixture models are a semi-parametric, which means that they partially depend on a set of predefined parameters. They are a good alternative to histogram analysis, which is non-parametric. Hence the mixture models provide greater flexibility and precision in modeling the underlying statistics of sample data. They are able to smooth over gaps resulting from sparse sample data and provide tighter constraints in assigning object membership to color-space regions. Such precision is necessary to obtain the best results possible from color-based pixel classification for qualitative segmentation requirements. Once a model is generated, conditional probabilities can be computed for color pixels.
What is a Gaussian Mixture Model?
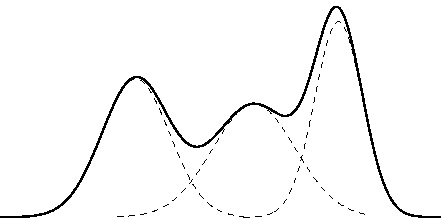 A Gaussian Mixture Model (GMM) is a parametric probability density function represented as a weighted sum of Gaussian component densities. GMMs are commonly used as a parametric model of the probability distribution of continuous measurements or features in a system. Gaussian mixture models can also be viewed as a form of generalised radial basis function network in which each Gaussian component is a basis function. The component priors can be viewed as weights in an output layer. GMM parameters are estimated from training data using the iterative Expectation-Maximization (EM) algorithm or Maximum A-Posteriori (MAP) estimation from a well-trained prior model.
A Gaussian Mixture Model (GMM) is a parametric probability density function represented as a weighted sum of Gaussian component densities. GMMs are commonly used as a parametric model of the probability distribution of continuous measurements or features in a system. Gaussian mixture models can also be viewed as a form of generalised radial basis function network in which each Gaussian component is a basis function. The component priors can be viewed as weights in an output layer. GMM parameters are estimated from training data using the iterative Expectation-Maximization (EM) algorithm or Maximum A-Posteriori (MAP) estimation from a well-trained prior model.
Where do we use GMMs?
Gaussian Mixture Models (GMMs) are among the most statistically mature methods for data modeling. Some of the more popular applications are:
- Speaker Identification: You can identify the person who is talking without having to depend on the actual words that are being uttered.
- Image Database Retrieval: Gaussian mixture models of texture and color are built to retrieve images quickly from a huge database
- Facial Expression Models: Analysis of facial expressions and building corresponding models for it.
- Economics: GMMs are used to model market fluctuations and volatility.
- Multimodal Biometric Verification: Using different parts of the body like eyes, fingers, voice, etc to build a robust biometric verification system.
————————————————————————————————-

One thought on “Gaussian Mixture Models”