 In machine learning, we use a lot of supervised learning models to analyze data and recognize patterns. If we consider the basic problem of binary classification, a machine learning algorithm takes a set of input data and predicts which of two possible classes a particular input belongs to. Kernel-classifiers comprise a powerful class of non-linear decision functions for binary classification. These classifiers are very useful when you cannot draw a straight line to separate two classes. The support vector machine (SVM) is a good example of a learning algorithm for kernel classifiers. It looks at all the boundaries and picks the one with the largest margin. It is widely used in many different fields and it has a very strong mathematical foundation. Now it is being claimed that Bayes Point Machine (BPM) is an improvement over SVM. Pretty bold claim! So what exactly is a BPM? How is it better than SVM?
In machine learning, we use a lot of supervised learning models to analyze data and recognize patterns. If we consider the basic problem of binary classification, a machine learning algorithm takes a set of input data and predicts which of two possible classes a particular input belongs to. Kernel-classifiers comprise a powerful class of non-linear decision functions for binary classification. These classifiers are very useful when you cannot draw a straight line to separate two classes. The support vector machine (SVM) is a good example of a learning algorithm for kernel classifiers. It looks at all the boundaries and picks the one with the largest margin. It is widely used in many different fields and it has a very strong mathematical foundation. Now it is being claimed that Bayes Point Machine (BPM) is an improvement over SVM. Pretty bold claim! So what exactly is a BPM? How is it better than SVM?
What is a Bayes Point Machine?
The Bayes Point Machine model was proposed by Herbrich et al. You can check out this paper to learn more about it. Discussing this topic without using machine learning lingo will make this post very lengthy, but I will try to keep it minimal. They present two algorithms to stochastically approximate the centre of mass of version space: a billiard sampling algorithm and a sampling algorithm based on the well known perceptron algorithm. Stochastic approximation refers to probabilistic approximation, a technique commonly used in mathematical optimization. It is shown how both algorithms can be extended to allow for soft-boundaries in order to admit training errors. Training errors happen when your training data is noisy or if your model is naive.
They show that, for the zero training error case, BPMs consistently outperform Support Vector Machines on both surrogate data and real-world benchmark data sets. In the soft-boundary/soft-margin case, the improvement over support vector machines is shown to be reduced. They also demonstrate that the real-valued output of single Bayes points on novel test points is a valid confidence measure and leads to a steady decrease in generalization error when used as a rejection criterion.
Kernel Classification
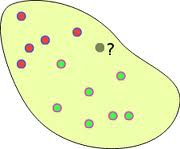 The paper explains a lot of the Bayesian viewpoint on kernel classification before going into the algorithm details. The paper proceeds by first defining a Bayes-optimal classifier. A Bayes-optimal classifier is a classifier that predicts, for any given point, the class that minimizes average error when marginalizing over all possible boundaries and all possible samplings of the data. The problem is that computing all the possibilities is ridiculously expensive. Imagine if there are a million datapoints, how long it would take to do all the calculations! So they decide to approximate this Bayes-optimal classifier by finding the boundary in a fixed space which is closest to this classifier in terms of the predictions it actually makes.
The paper explains a lot of the Bayesian viewpoint on kernel classification before going into the algorithm details. The paper proceeds by first defining a Bayes-optimal classifier. A Bayes-optimal classifier is a classifier that predicts, for any given point, the class that minimizes average error when marginalizing over all possible boundaries and all possible samplings of the data. The problem is that computing all the possibilities is ridiculously expensive. Imagine if there are a million datapoints, how long it would take to do all the calculations! So they decide to approximate this Bayes-optimal classifier by finding the boundary in a fixed space which is closest to this classifier in terms of the predictions it actually makes.
This approximation is defined by randomly drawing some test points, evaluating the Bayes-optimal prediction on these points. We then search over all hypotheses for the one which is closest to the Bayes-optimal predictions. It means that we form our model based on a few points and see if it fits all the other points. The usual stuff! This is unfortunately still really slow in the general case. So the authors turn to linear classifiers. A linear classifier is a classifier that draws straight line between two classes. For any new input, it sees which side of the boundary this point lies.
SVM vs BPM
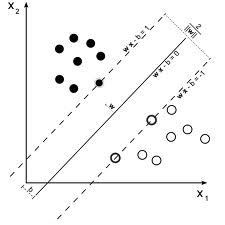 Given a training set with zero training error, they prove that the center of mass of the subset of all possible 1-norm vectors that correctly classify the training set is a good approximation to the Bayes-optimal classifier. 1-norm vectors, you say? The concept of “norm” is explained nicely here. Then, they prove that the SVM can be derived as an approximation of this Bayes-point classifier, and also that this Bayes-point classifier admits a kernel representation. So what we were getting at, all this while, is that SVMs are an approximations of BPMs. This implies that BPMs are more accurate than SVMs, or at least they claim so!
Given a training set with zero training error, they prove that the center of mass of the subset of all possible 1-norm vectors that correctly classify the training set is a good approximation to the Bayes-optimal classifier. 1-norm vectors, you say? The concept of “norm” is explained nicely here. Then, they prove that the SVM can be derived as an approximation of this Bayes-point classifier, and also that this Bayes-point classifier admits a kernel representation. So what we were getting at, all this while, is that SVMs are an approximations of BPMs. This implies that BPMs are more accurate than SVMs, or at least they claim so!
There are a few more details of the algorithm that they propose to improve the efficiency. You can read the paper to know more about it. It usually takes some time for a new algorithm to get accepted in the machine learning community. It has to stand the test of time and has to perform well across multiple databases. The point of this blog post was to introduce you to the concept of BPM. It’s a little too mathematical to give general analogies. So people outside of machine learning might find this post a bit difficult to understand.
The railway picture still doesn’t make sense. What is it supposed to depict?
Well, the thing just outside the rails in that picture is called a Point Machine. A point machine is a device for operating railway turnouts, especially at a distance. So technically, given the title of this blog post, it is not completely random!
————————————————————————————————-
