 Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
Tag: SVM
What’s The Importance Of Hyperparameters In Machine Learning?
 Machine learning is becoming increasingly relevant in all walks of science and technology. In fact, it’s an integral part of many fields like computer vision, natural language processing, robotics, e-commerce, spam filtering, and so on. The list is potential applications is pretty huge! People working on machine learning tend to build models based on training data, in the hope that those models will perform well on unseen data. As we all know, every model has some parameters associated with it. We want our machine learning models to estimate these parameters from the training data. But as it turns out, there are a few parameters that cannot be estimated using this procedure. These parameters tend have a significant impact on the performance of your model. Now why is that? Where do these parameters come from? How do we deal with this? Continue reading “What’s The Importance Of Hyperparameters In Machine Learning?”
Machine learning is becoming increasingly relevant in all walks of science and technology. In fact, it’s an integral part of many fields like computer vision, natural language processing, robotics, e-commerce, spam filtering, and so on. The list is potential applications is pretty huge! People working on machine learning tend to build models based on training data, in the hope that those models will perform well on unseen data. As we all know, every model has some parameters associated with it. We want our machine learning models to estimate these parameters from the training data. But as it turns out, there are a few parameters that cannot be estimated using this procedure. These parameters tend have a significant impact on the performance of your model. Now why is that? Where do these parameters come from? How do we deal with this? Continue reading “What’s The Importance Of Hyperparameters In Machine Learning?”
Bayes Point Machines
 In machine learning, we use a lot of supervised learning models to analyze data and recognize patterns. If we consider the basic problem of binary classification, a machine learning algorithm takes a set of input data and predicts which of two possible classes a particular input belongs to. Kernel-classifiers comprise a powerful class of non-linear decision functions for binary classification. These classifiers are very useful when you cannot draw a straight line to separate two classes. The support vector machine (SVM) is a good example of a learning algorithm for kernel classifiers. It looks at all the boundaries and picks the one with the largest margin. It is widely used in many different fields and it has a very strong mathematical foundation. Now it is being claimed that Bayes Point Machine (BPM) is an improvement over SVM. Pretty bold claim! So what exactly is a BPM? How is it better than SVM? Continue reading “Bayes Point Machines”
In machine learning, we use a lot of supervised learning models to analyze data and recognize patterns. If we consider the basic problem of binary classification, a machine learning algorithm takes a set of input data and predicts which of two possible classes a particular input belongs to. Kernel-classifiers comprise a powerful class of non-linear decision functions for binary classification. These classifiers are very useful when you cannot draw a straight line to separate two classes. The support vector machine (SVM) is a good example of a learning algorithm for kernel classifiers. It looks at all the boundaries and picks the one with the largest margin. It is widely used in many different fields and it has a very strong mathematical foundation. Now it is being claimed that Bayes Point Machine (BPM) is an improvement over SVM. Pretty bold claim! So what exactly is a BPM? How is it better than SVM? Continue reading “Bayes Point Machines”
Kernel Functions For Machine Learning
 You must have heard the term ‘kernel’ floating around quite a few times. People from many different backgrounds use it in different contexts. The thing is that this term has been applied to different things in different domains. When we talk about operating systems, we talk about which kernel is being used. Kernel is also used extensively in parallel computing and in the GPU domain, where it is the function which is called repetitively on a computing grid. It has a few other meanings in different hardware related programming fields. But in this post, I will discuss kernels as applied to machine learning. Kernels are used in machine learning to transform the data so that the classification becomes easier. One common thing in all these different definitions of the term ‘kernel’ is that it is being used as a bridge between two things. In operating systems, it is the bridge between hardware and software. In GPU domain, it is the bridge between the geometric grid and the programmer. In machine learning, it is the bridge between linearity and non-linearity. I will discuss the underlying mathematical structure in this post. So readers beware, this is a technical deep-dive. Continue reading “Kernel Functions For Machine Learning”
You must have heard the term ‘kernel’ floating around quite a few times. People from many different backgrounds use it in different contexts. The thing is that this term has been applied to different things in different domains. When we talk about operating systems, we talk about which kernel is being used. Kernel is also used extensively in parallel computing and in the GPU domain, where it is the function which is called repetitively on a computing grid. It has a few other meanings in different hardware related programming fields. But in this post, I will discuss kernels as applied to machine learning. Kernels are used in machine learning to transform the data so that the classification becomes easier. One common thing in all these different definitions of the term ‘kernel’ is that it is being used as a bridge between two things. In operating systems, it is the bridge between hardware and software. In GPU domain, it is the bridge between the geometric grid and the programmer. In machine learning, it is the bridge between linearity and non-linearity. I will discuss the underlying mathematical structure in this post. So readers beware, this is a technical deep-dive. Continue reading “Kernel Functions For Machine Learning”
Support Vector Machines
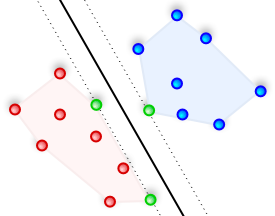
 In machine learning, we have supervised learning on one end and unsupervised learning on the other end. Support Vector Machines (SVMs) are supervised learning models used to analyze and classify data. We use machine learning algorithms to train the machines. Once we have a model, we can classify unknown data. Let’s say you have a set of data points and they belong one of the two possible classes. Now our task is to find the best possible way to put a boundary between the two sets of points. When a new point comes in, we can use this boundary to decide whether it belongs to class 1 or class 2. In real life, these data points can be a set of observations like images, text, characters, protein sequences etc. How can we achieve this in the most optimal way? Continue reading “Support Vector Machines”
In machine learning, we have supervised learning on one end and unsupervised learning on the other end. Support Vector Machines (SVMs) are supervised learning models used to analyze and classify data. We use machine learning algorithms to train the machines. Once we have a model, we can classify unknown data. Let’s say you have a set of data points and they belong one of the two possible classes. Now our task is to find the best possible way to put a boundary between the two sets of points. When a new point comes in, we can use this boundary to decide whether it belongs to class 1 or class 2. In real life, these data points can be a set of observations like images, text, characters, protein sequences etc. How can we achieve this in the most optimal way? Continue reading “Support Vector Machines”
