 Machine learning is becoming increasingly relevant in all walks of science and technology. In fact, it’s an integral part of many fields like computer vision, natural language processing, robotics, e-commerce, spam filtering, and so on. The list is potential applications is pretty huge! People working on machine learning tend to build models based on training data, in the hope that those models will perform well on unseen data. As we all know, every model has some parameters associated with it. We want our machine learning models to estimate these parameters from the training data. But as it turns out, there are a few parameters that cannot be estimated using this procedure. These parameters tend have a significant impact on the performance of your model. Now why is that? Where do these parameters come from? How do we deal with this?
Machine learning is becoming increasingly relevant in all walks of science and technology. In fact, it’s an integral part of many fields like computer vision, natural language processing, robotics, e-commerce, spam filtering, and so on. The list is potential applications is pretty huge! People working on machine learning tend to build models based on training data, in the hope that those models will perform well on unseen data. As we all know, every model has some parameters associated with it. We want our machine learning models to estimate these parameters from the training data. But as it turns out, there are a few parameters that cannot be estimated using this procedure. These parameters tend have a significant impact on the performance of your model. Now why is that? Where do these parameters come from? How do we deal with this?
Why do we need to talk about hyperparameters?
To understand why we need this, let’s consider the following example. Let’s say our friend, Michael, is trying out a new sweet dish recipe and he wants to know whether or not it tastes good. So to test it out, he invites 10 people to his house to taste the dish so that he can gather some feedback. After the first round, 4 people say that the dish is too sweet, 3 people say that there is too much nutmeg, and remaining 3 people say that it’s just fine. So now, based on the collective feedback of those 10 people, he needs to alter the ingredients so that the overall feedback becomes positive. If he just caters to the needs of the first 4 people, then the remaining people will be unhappy. So he has to take everything into consideration and keep iterating until everyone is happy. This is be the general procedure one would follow to optimize the ingredients.
Now, for some reason, everyone is saying that there is a hint of cinnamon in the dish and that it’s not blending well. This is puzzling to Michael because he didn’t even add cinnamon to the sweet dish. What might have happened? Well, as it turns out, somebody else had used the container the previous day and had used a lot of cinnamon. Now, when you use the same container, it’s adding the cinnamon flavor. This is something that’s not under his control, but it is affecting his sweet dish. Now, he has to do something to neutralize the cinnamon taste. Do you see where I’m going with this?
Similar to what happened to Michael’s sweet dish, there are some parameters that affect our machine learning model. We cannot estimate these parameters directly, but we need to account for them. These parameters are called hyperparameters, and they are very crucial in machine learning.
What exactly is a hyperparameter?
The concept of hyperparameter actually comes in the field of statistics. Let’s say you are modeling some data coming out of a system. You know that it has Gaussian distribution, and so you are trying to estimate the mean and variance of the distribution. Now, if the mean itself follows Poisson distribution with parameter λ (lambda), then we say that λ is the hyperparameter of the system. Hyperparameter is a parameter that governs the parameters of a system. We may have some Inception-style action going on here! Hyperparameters are frequently used in Support Vector Machines (SVM).
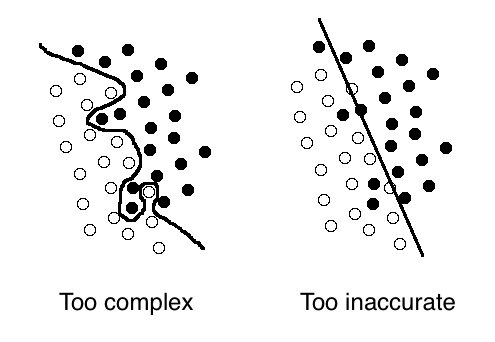 Let’s consider an SVM with an RBF kernel. Our goal is to estimate the best possible boundaries between our classes in the training data. The decision boundaries affect the classification accuracy directly, and so we can estimate the parameters related to those boundaries during training. What would be the hyperparameters in this situation? Well, as we know, when we are dealing with complex data, we are faced with the curse of dimensionality. This means that the high dimensionality of the data makes it prohibitively expensive to build a very accurate classifier. So we want the boundaries to be smooth and simple. But if we make it smooth and simple, we won’t be able to model the training data accurately because there will some misclassified samples. So as you can see, it’s a bit of a trade off. This trade-off is quantified by a parameter called ‘C’.
Let’s consider an SVM with an RBF kernel. Our goal is to estimate the best possible boundaries between our classes in the training data. The decision boundaries affect the classification accuracy directly, and so we can estimate the parameters related to those boundaries during training. What would be the hyperparameters in this situation? Well, as we know, when we are dealing with complex data, we are faced with the curse of dimensionality. This means that the high dimensionality of the data makes it prohibitively expensive to build a very accurate classifier. So we want the boundaries to be smooth and simple. But if we make it smooth and simple, we won’t be able to model the training data accurately because there will some misclassified samples. So as you can see, it’s a bit of a trade off. This trade-off is quantified by a parameter called ‘C’.
Another hyperparameter would be the amount of influence each training sample would have on the model. This is quantified by γ (gamma). Since it’s a RBF kernel (also called a Gaussian kernel), we use the Gaussian model to apply the kernel to any two samples. This means that the variance factor, denoted by σ, would have an influence on how far each training sample can reach. If you apply the RBF kernel to two samples, it will be something like this:
K(x, x’) = exp(-||(x-x’)||2 / 2*σ2)
Here, gamma is given by:
γ = -1/2*σ2
A higher variance would mean more spread, and hence more influence on the neighboring samples. So depending on the values you choose for γ, your training samples will influence their neighbors accordingly.
How do we estimate these parameters?
Tuning C and γ correctly is a vital step in the use of SVMs. C directly helps us in minimizing the structural risk of the overall system, and usually tends to have more impact that γ. Let’s jump into machine learning lingo for a minute here. In an SVM, the decision hyperplane is quantified by the weights. The parameter C enforces an upper bound on the norm of the weights. This means that as we increase C, we increase the complexity of the decision hyperplane. If we just slightly increase C, we can still form all of the linear models that we could before along with a few that we couldn’t. The reason for this is because we increased the upper bound on the allowable norm of the weights, which in turn allowed us to form a few more. So we can basically control the complexity of the decision hyperplane by controlling C. Unfortunately, the theory for determining how to set these hyperparameters is not very well developed at the moment. There is no parametric method available to estimate the values of these hyperparameters, so most people tend to use cross-validation.
Basically, we estimate the best value of C using a technique called grid search. It is a pseudo brute force method where we pick a few values of C and give that as the input to our SVM model. We then use k-fold cross validation to compute the performance for each case. Depending on the output, we can pick a second set of values for C with higher granularity based on where the performance peaked. The same is applicable to the estimation of γ as well. Once we have a good estimate, we fix them and then train our SVM. Tuning the hyperparameters tends to have a significant impact on the overall accuracy of the system. So once you hit a plateau with your SVM, think in terms of hyperparameters!
—————————————————————–—————————————–
