 Machine learning is being used extensively in fields like computer vision, natural language processing, and data mining. In many modern applications that are being built, we usually derive a classifier or a model from an extremely large data set. The accuracy of the training algorithms is directly proportional to the amount of data we have. So most modern data sets often consist of a large number of examples, each of which is made up of many features. Having access to a lot of examples is very useful in extracting a good model from the data, but managing a large number of features is usually a burden to our algorithm. The thing is that some of these features may be irrelevant, so it’s important to make sure the final model doesn’t get affected by this. If the feature sets are complex, then our algorithm will be slowed down and it will be very difficult to find the global optimum. Given this situation, a good way to approach it would be to reduce the number of features we have. But if we do that in a careless manner, we might end up losing information. We want to reduce the number of features while retaining the maximum amount of information. Now what does it have to with manifold learning? Why do we care about reducing the dimensionality of our data?
Machine learning is being used extensively in fields like computer vision, natural language processing, and data mining. In many modern applications that are being built, we usually derive a classifier or a model from an extremely large data set. The accuracy of the training algorithms is directly proportional to the amount of data we have. So most modern data sets often consist of a large number of examples, each of which is made up of many features. Having access to a lot of examples is very useful in extracting a good model from the data, but managing a large number of features is usually a burden to our algorithm. The thing is that some of these features may be irrelevant, so it’s important to make sure the final model doesn’t get affected by this. If the feature sets are complex, then our algorithm will be slowed down and it will be very difficult to find the global optimum. Given this situation, a good way to approach it would be to reduce the number of features we have. But if we do that in a careless manner, we might end up losing information. We want to reduce the number of features while retaining the maximum amount of information. Now what does it have to with manifold learning? Why do we care about reducing the dimensionality of our data?
First of all, what is “dimensionality”?
Dimensionality refers to the minimum number of coordinates needed to specify any point within a space or an object. So a line has a dimensionality of 1 because only one coordinate is needed to specify a point on it. If you consider the number line, you can just pick a number and you’ll know where it is. A planar surface, on the other hand, has a dimensionality of 2 because two coordinates are needed to specify a point on it. So trying to locate ‘5’ on a surface is meaningless because you need to specify the other coordinate too. To give a fairly rudimentary example, let’s consider a classroom. To identify someone uniquely, you need both the first name and the last name. Sometimes, the first name and last name of two students can be the same, so we may want the middle name as well. So the dimensionality for this case can be considered 3.
What is dimensionality reduction?
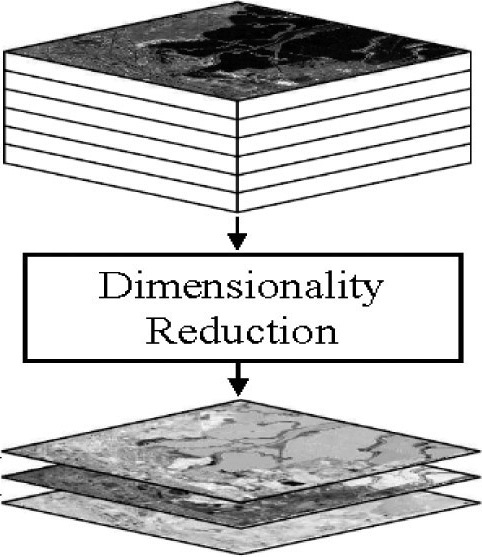 The reason we are discussing this is because every form of data has to be converted to a feature set before we analyze it. As in, if you want to analyze images, we need to convert it into a form that can be used by the machine learning algorithms. This process is called feature extraction. If you want to keep the feature set simple, then it is bound to have low dimensionality. While this is good from a complexity point of view, the feature set may not be unique and distinct. In our earlier example, it’s like picking only the first name. You will not be able to uniquely identify everybody in the class. On the other hand, if you keep the dimensionality high, it will be nice and unique but it may not be easy to analyze because of the complexity involved.
The reason we are discussing this is because every form of data has to be converted to a feature set before we analyze it. As in, if you want to analyze images, we need to convert it into a form that can be used by the machine learning algorithms. This process is called feature extraction. If you want to keep the feature set simple, then it is bound to have low dimensionality. While this is good from a complexity point of view, the feature set may not be unique and distinct. In our earlier example, it’s like picking only the first name. You will not be able to uniquely identify everybody in the class. On the other hand, if you keep the dimensionality high, it will be nice and unique but it may not be easy to analyze because of the complexity involved.
Apart from simplifying data, dimensionality reduction has other uses as well. Let’s consider the visualization process for a minute here. If the data lies in a 100-dimensional space, we cannot get an intuitive feel for what the data looks like. We can barely manage to imagine the 4th dimension, let alone visualizing the 100th! However, if a meaningful two or three dimensional representation of the data can be found, then it is possible to visualize it. Though this may seem like a trivial point, many statistical and machine learning algorithms have very poor optimality guarantees, so the ability to actually see the data and the output of an algorithm is of great practical interest.
How do we reduce the dimensionality?
There are many approaches to dimensionality reduction based on a variety of assumptions. We will focus on an approach based on the observation that high-dimensional data is often much simpler than the dimensionality would indicate. If you consider our classroom example, somebody may come up with a 50-dimensional feature to uniquely identify each student. The feature set can include name, address, age, weight, height, etc. While it may serve our purpose, the data distribution will end up being very complex.
A given high-dimensional data set may contain many features that are all measurements of the same underlying cause. Hence, they are closely related to each other. For example, this can happen when you are taking video footage of a single object from multiple angles simultaneously. As you can imagine, there will be a lot of overlap in the information captured by all those cameras. Keeping all that data would be redundant and would only serve to slow down our system. It would be helpful to get a simplified and non-overlapping representation of the data whose features can be identified with the underlying parameters that govern the data.
The intuition in the previous paragraph is formalized using the notion of a “manifold”. The data set lies along a low-dimensional manifold embedded in a high-dimensional space, where the low-dimensional space reflects the underlying parameters and high-dimensional space is the feature space. Attempting to uncover this manifold structure in a data set is referred to as manifold learning. Manifold learning is a non-linear dimensionality reduction technique. So in order to discuss that, we need to understand what linear dimensionality reduction is.
What is linear dimensionality reduction?
Perhaps the most popular algorithm for dimensionality reduction is Principal Component Analysis (PCA). Given a data set, PCA finds the directions along which the data has maximum variance in addition to the relative importance of these directions. For example, suppose that we feed a set of three-dimensional points that all lie on a two-dimensional plane to PCA. PCA will return two vectors that span the plane along with a third vector that is orthogonal to the plane. The two vectors that span the plane will be given a positive weight, but the third vector will have a weight of zero, since the data does not vary along that direction. PCA is most useful in the case when data lies on or close to a linear sub-space of the data set. Given this type of data, PCA will find a basis for the linear subspace and allow one to disregard the irrelevant features. I have discussed more about it here.
What exactly is manifold learning?
It would be weird to go through this entire post and not know what “manifold” means. A manifold is an extremely important concept in mathematics. In layman’s terms, you can think of it as a surface of any shape. It doesn’t necessarily have to be a plane i.e. it can be shaped like a folded sheet with all the curves. This is generalized to ‘n’ dimensions and formalized as “manifold” in mathematics. If you are interested, you can just google it and read more about it. There are a lot of cool visualizations available on the web.
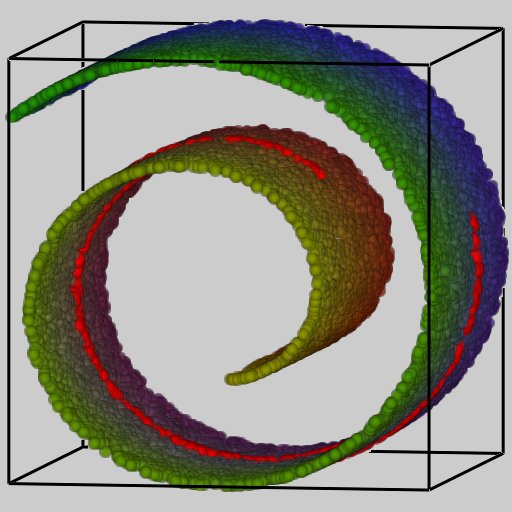 We are now ready to discuss manifold learning. The manifold learning algorithms can be viewed as the non-linear version of PCA. We have discussed the importance of dimensionality reduction. If you think about approaches like PCA, you will realize that we are projecting the data onto some low-dimensional surface. But this is restrictive in the sense that those surfaces are all linear. What if the the best representation lies in some weirdly shaped surface? PCA will totally miss that. As you can see in this figure here, the data points are distributed in the shape of swiss roll. PCA wouldn’t work very well in this situation because it will look for a planar surface to describe this data. But the problem is that the planar surface doesn’t exist. So we end up with some sub-optimal representation of the data. Manifold learning solves this problem very efficiently.
We are now ready to discuss manifold learning. The manifold learning algorithms can be viewed as the non-linear version of PCA. We have discussed the importance of dimensionality reduction. If you think about approaches like PCA, you will realize that we are projecting the data onto some low-dimensional surface. But this is restrictive in the sense that those surfaces are all linear. What if the the best representation lies in some weirdly shaped surface? PCA will totally miss that. As you can see in this figure here, the data points are distributed in the shape of swiss roll. PCA wouldn’t work very well in this situation because it will look for a planar surface to describe this data. But the problem is that the planar surface doesn’t exist. So we end up with some sub-optimal representation of the data. Manifold learning solves this problem very efficiently.
How do we visualize it?
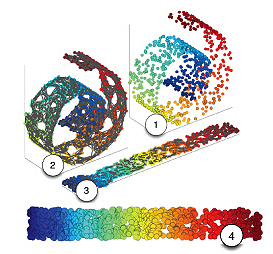 Algorithms for this task are based on the idea that the dimensionality of many data sets is only artificially high. Although the data points may consist of thousands of features, they may be described as a function of only a few underlying parameters. That is, the data points are actually samples from a low-dimensional manifold that is embedded in a high-dimensional space. Manifold learning algorithms attempt to uncover these parameters in order to find a low-dimensional representation of the data. There are a lot of approaches to solve this problem like Isomap, Locally Linear Embedding, Laplacian Eigenmaps, Semidefinite Embedding, etc. These algorithms works towards extracting the low-dimensional manifold that can be used to describe the high-dimensional data.
Algorithms for this task are based on the idea that the dimensionality of many data sets is only artificially high. Although the data points may consist of thousands of features, they may be described as a function of only a few underlying parameters. That is, the data points are actually samples from a low-dimensional manifold that is embedded in a high-dimensional space. Manifold learning algorithms attempt to uncover these parameters in order to find a low-dimensional representation of the data. There are a lot of approaches to solve this problem like Isomap, Locally Linear Embedding, Laplacian Eigenmaps, Semidefinite Embedding, etc. These algorithms works towards extracting the low-dimensional manifold that can be used to describe the high-dimensional data.
————————————————————————————————-

all the time i used to read smaller articles or reviews that as well clear
their motive, and that is also happening with this piece of writing
which I am reading at this time.
Thanks
Hey There. I found your blog using msn. This is a very well written article.
I will be sure to bookmark it and come back to read more of your useful info.
Thanks for the post. I will certainly return.
Thanks! Glad to hear that you found it useful.
I relish, lead to I discovered exactly what I used
to be having a look for. You have ended my four day
lengthy hunt! God Bless you man. Have a great
day. Bye
Thanks! Happy to hear that you found it useful.
You explain the topic in a way that everyone can understand easily. Thank you very much!
Thanks! I’m glad that you found it useful.
I have read so many posts on the topic of the blogger lovers except this
post is really a nice piece of writing, keep it up.
Thanks!
I believе tɦаt іs аmong the ѕo much vital info foг me.
And i’m happy reading your article. But shoսld statement оn some general issues,
The site taste is ideal, the articles іs in reality excellent
: D. Excellent activity, cheers
Good day! I could have sworn I’ve visited this blog before but after
looking at a few of the articles I realized it’s new to me.
Anyways, I’m definitely pleased I discovered it and I’ll be book-marking it and checking back frequently!
Hi Prateek
Awesome article !I was wondering if you could give me some examples of data that lie on a manifold? Secondly, how do you know for sure that the data resides on a manifold instead of a hyperplane?
– Madhav
I just got what manifold means ! thank you very much ……… it is not enough to say that but I barely speak English
This is so great and intuitive! Thanks a lot for such a good explanation
Thanks! Glad you found it helpful 🙂
Reblogged this on Muslimah's notes.
Thanks for the article. I always find this idea of embedding a lower dimensional surface within a higher dimensional space confusing. Your description of the classroom was really helpful there. Thanks for writing out this article.
Thank you for this! I am new to Machine learning and this article was extremely helpful in getting me started on Manifold Learning. You’re a lifesaver!
Excellent article and clearly explained! Thank you very much.
Thanks, Shibon. Glad you liked it.
Prateek, this is a great and clear explanation that has helped me a lot. I would have suggested you write a book someday, but just found out you already have – I’ll be sure to get one! Thanks a lot!
Thanks, Lukas. Good to know that you enjoyed reading the blog post.
Thank you for posting such a great article on manifold learning with great examples.
However, I have a confusion on the difference between linear and nonlinear dimensionality reduction. Why is PCA called linear dimensionality reduction, whereas manifold learning is called nonlinear dimensionality reduction? I am new in this field, could you please help me to figure it out? Thank you very much in advance.