 In the previous two blog posts, we discussed why Hidden Markov Models and Feedforward Neural Networks are restrictive. If we want to build a good sequential data model, we should give more freedom to our learning model to understand the underlying patterns. This is where Recurrent Neural Networks (RNNs) come into picture. One of the biggest restrictions of Convolutional Neural Networks is that they force us to operate on fixed size input data. RNNs know how to operate on sequences of data, which is exciting because it opens up a lot of possibilities! What are RNNs? How do we construct them?
In the previous two blog posts, we discussed why Hidden Markov Models and Feedforward Neural Networks are restrictive. If we want to build a good sequential data model, we should give more freedom to our learning model to understand the underlying patterns. This is where Recurrent Neural Networks (RNNs) come into picture. One of the biggest restrictions of Convolutional Neural Networks is that they force us to operate on fixed size input data. RNNs know how to operate on sequences of data, which is exciting because it opens up a lot of possibilities! What are RNNs? How do we construct them?
What exactly are RNNs?
In order to understand RNNs, you need to have some background in deep feedforward neural networks. If you need a refresher, you can go through this blog post. If you know Caffe, then you can also go through this blog post to understand the implementation of Convolutional Neural Networks better. As we know, a feedforward neural network consists of interconnected layers, where each layer consists of neurons. RNNs are built using the same types of neurons, but the layer connectivity patterns are different.
In order to simplify the training process, feedforward neural networks assume that the information flows in a single direction i.e. from the input layer to the output layer. This is actually an artificial restriction imposed by us. Human brain doesn’t work this way! The brain use a lot of feedback mechanism to optimize the learning process. So RNNs allow us to design networks in a way that allows for directed cycles of connectivity within neurons.
Show and tell
Let’s just compare the structure of feedforward neural networks against RNNs to get a better idea:
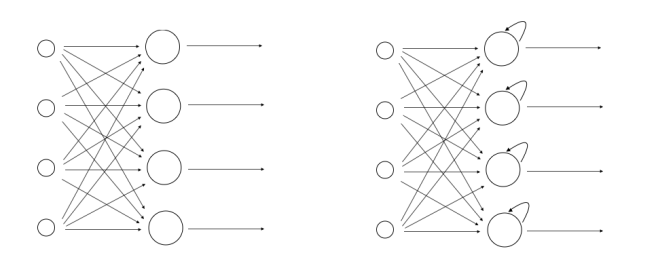
The figure on the left indicates a typical feedforward neural network and the figure on the right indicates an RNN. As we can see, a neuron can feed its own output to itself in an RNN. This forms a directed loop that allows RNNs to learn in a better way.
RNN in action
Let’s see how RNN is able to model a sequence of events. Consider the following waveform:

Now we want the RNN to learn about this waveform and then build a relationship between the input data and the output waveform. A trained RNN should be able to detect the pattern and then simulate it for sequences of arbitrary lengths. Let’s see the results:

As we can see from the above figure, the RNN closely matches the ground truth. So how does an RNN achieve this? The first thing an RNN does is it initializes all the hidden activities to a predefined state. The fundamental principle remains the same. At each step in the sequence, every neuron in the hidden layers sends information to all its outgoing connections, including itself. It will then update itself by computing the weighted sum of its inputs and then passing this value through an activation function like sigmoid, tanh, softmax, and so on. Now the important thing to note is that the RNN is able to retain the “memory” of previous events. How does it do this? Each neuron in the RNN uses its previous output information is used to compute the current state in each time step. This allows it to learn the sequence of events and model the process very efficiently.
——————————————————————————————————————
