 There is a lot of data being generated in today’s digital world, so there is a high demand for real time data analytics. This data usually comes in bits and pieces from many different sources. It can come in various forms like words, images, numbers, and so on. Twitter is a good example of words being generated in real time. We also have websites where statistics like number of visitors, page views, and so on are being generated in real time. There are so much data that it is not very useful in its raw form. We need to process it and extract insights from it so that it becomes useful. This is where Spark Streaming comes into the picture! It is exceptionally good at processing real time data and it is highly scalable. It can process enormous amounts of data in real time without skipping a beat. So how exactly does Spark do it? How do we use it? Continue reading “Analyzing Real-time Data With Spark Streaming In Python”
There is a lot of data being generated in today’s digital world, so there is a high demand for real time data analytics. This data usually comes in bits and pieces from many different sources. It can come in various forms like words, images, numbers, and so on. Twitter is a good example of words being generated in real time. We also have websites where statistics like number of visitors, page views, and so on are being generated in real time. There are so much data that it is not very useful in its raw form. We need to process it and extract insights from it so that it becomes useful. This is where Spark Streaming comes into the picture! It is exceptionally good at processing real time data and it is highly scalable. It can process enormous amounts of data in real time without skipping a beat. So how exactly does Spark do it? How do we use it? Continue reading “Analyzing Real-time Data With Spark Streaming In Python”
How To Compute Confidence Measure For SVM Classifiers
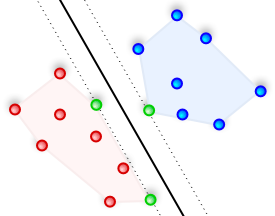 Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
How To Edit Videos Using FFmpeg
 Editing videos can be a huge pain if you don’t have the right tools. We know that there are a lot of tools available for image editing. You can quickly crop, resize, or manipulate an image without skipping a beat, but you can’t do the same for videos. Let’s say you want to resize a video, extract a 10 second segment from it, and then convert it to a different format. Can you do it quickly? Well, not unless you know how to use some bloated software whose GUI usually has a steep learning curve! A lot of people tend to get stuck when they want to play around with videos. The good news is that you don’t need some fancy commercial software to edit videos. FFmpeg is here for you and you can do a lot of things with it. Let’s go ahead and see how to manipulate a video using this amazing tool, shall we? Continue reading “How To Edit Videos Using FFmpeg”
Editing videos can be a huge pain if you don’t have the right tools. We know that there are a lot of tools available for image editing. You can quickly crop, resize, or manipulate an image without skipping a beat, but you can’t do the same for videos. Let’s say you want to resize a video, extract a 10 second segment from it, and then convert it to a different format. Can you do it quickly? Well, not unless you know how to use some bloated software whose GUI usually has a steep learning curve! A lot of people tend to get stuck when they want to play around with videos. The good news is that you don’t need some fancy commercial software to edit videos. FFmpeg is here for you and you can do a lot of things with it. Let’s go ahead and see how to manipulate a video using this amazing tool, shall we? Continue reading “How To Edit Videos Using FFmpeg”
Launching A Spark Standalone Cluster
 In the previous blog post, we saw how to start a Spark cluster on EC2 using the inbuilt launch scripts. This is good if you want get something up and running quickly, but it won’t allow fine-grained control over our cluster. A lot of times, we would want to customize the machines that we spin up. Let’s say that you want to use different types of machines to handle production level traffic in different regions. May be you are not on EC2 and you want to launch some machines in your cluster. How would you do it? This is the reason we have Spark Standalone mode. Using this method, we can manually launch any number of machines independently in our private cluster and make them listen to our master machine. It gives us a lot of flexibility! Let’s go ahead and see how to do it, shall we? Continue reading “Launching A Spark Standalone Cluster”
In the previous blog post, we saw how to start a Spark cluster on EC2 using the inbuilt launch scripts. This is good if you want get something up and running quickly, but it won’t allow fine-grained control over our cluster. A lot of times, we would want to customize the machines that we spin up. Let’s say that you want to use different types of machines to handle production level traffic in different regions. May be you are not on EC2 and you want to launch some machines in your cluster. How would you do it? This is the reason we have Spark Standalone mode. Using this method, we can manually launch any number of machines independently in our private cluster and make them listen to our master machine. It gives us a lot of flexibility! Let’s go ahead and see how to do it, shall we? Continue reading “Launching A Spark Standalone Cluster”
How To Launch A Spark Cluster On Amazon EC2
 Apache Spark is marketed as “lightning fast cluster computing” and it stands true to its word! It can do amazing things really quickly using a cluster of machines. So how do we assemble that cluster? Let’s say you are using a cloud service provider like Amazon Web Services. Do we need to spin up a bunch of instances ourselves to form a “cluster”? Well, not really! Spark can launch a cluster by itself and you can control everything from one machine. You just need to log into your main instance and Spark will automatically launch all the instances in the cluster for you. It’s beautiful! Let’s go ahead and see how to launch a cluster, shall we? Continue reading “How To Launch A Spark Cluster On Amazon EC2”
Apache Spark is marketed as “lightning fast cluster computing” and it stands true to its word! It can do amazing things really quickly using a cluster of machines. So how do we assemble that cluster? Let’s say you are using a cloud service provider like Amazon Web Services. Do we need to spin up a bunch of instances ourselves to form a “cluster”? Well, not really! Spark can launch a cluster by itself and you can control everything from one machine. You just need to log into your main instance and Spark will automatically launch all the instances in the cluster for you. It’s beautiful! Let’s go ahead and see how to launch a cluster, shall we? Continue reading “How To Launch A Spark Cluster On Amazon EC2”
Getting Started With Apache Spark In Python
 In one of the previous blog posts, we discussed how to get Apache Spark up and running on your Ubuntu box. In this post, we will start exploring it. One of the best things about Spark is that it comes with a Python API that works like a charm! The API also available in Java, Scala, and R. That pretty much covers the entire world of programming and data science! Spark’s shell provides a great way to analyze our data and work with it interactively. We are going to see how to interact with Spark Python API in this post. You would have downloaded Spark on your machine. Let’s go into “spark-1.5.1” directory on your terminal and get started, shall we? Continue reading “Getting Started With Apache Spark In Python”
In one of the previous blog posts, we discussed how to get Apache Spark up and running on your Ubuntu box. In this post, we will start exploring it. One of the best things about Spark is that it comes with a Python API that works like a charm! The API also available in Java, Scala, and R. That pretty much covers the entire world of programming and data science! Spark’s shell provides a great way to analyze our data and work with it interactively. We are going to see how to interact with Spark Python API in this post. You would have downloaded Spark on your machine. Let’s go into “spark-1.5.1” directory on your terminal and get started, shall we? Continue reading “Getting Started With Apache Spark In Python”
Understanding Filter, Map, And Reduce In Python
 Even though lot of people use Python in an object oriented style, it has several functions that enable functional programming. For those of you who don’t know, functional programming is a programming paradigm based on lambda calculus that treats computation as an evaluation of mathematical functions. Some of prominent functional programming languages include Scala, Haskell, Clojure, and so on. You should go through this nice article on functional programming that explains it in layman’s terms. Coming back to the topic at hand, Python provides features like lambda, filter, map, and reduce that can basically cover most of what you would need to operate on data. Let’s go ahead and play with them to understand their awesomeness, shall we? Continue reading “Understanding Filter, Map, And Reduce In Python”
Even though lot of people use Python in an object oriented style, it has several functions that enable functional programming. For those of you who don’t know, functional programming is a programming paradigm based on lambda calculus that treats computation as an evaluation of mathematical functions. Some of prominent functional programming languages include Scala, Haskell, Clojure, and so on. You should go through this nice article on functional programming that explains it in layman’s terms. Coming back to the topic at hand, Python provides features like lambda, filter, map, and reduce that can basically cover most of what you would need to operate on data. Let’s go ahead and play with them to understand their awesomeness, shall we? Continue reading “Understanding Filter, Map, And Reduce In Python”
How To Install Apache Spark On Ubuntu
 There’s so much data being generated in today’s world that we need platforms and frameworks that it’s mind boggling. This field of study is called Big Data Analysis. With so much data lying around, often ranging in petabytes and exabytes, we need super powerful systems to process it. Not only that, we need to do it high efficiency. If you try to do it using your regular ways, you will never be able to do anything in time, let alone doing it in real-time. This is where Apache Spark comes into picture. It is an open source big data processing framework that can process massive amounts of data at high speed using cluster computing. Let’s see how we can install it on Ubuntu. Continue reading “How To Install Apache Spark On Ubuntu”
There’s so much data being generated in today’s world that we need platforms and frameworks that it’s mind boggling. This field of study is called Big Data Analysis. With so much data lying around, often ranging in petabytes and exabytes, we need super powerful systems to process it. Not only that, we need to do it high efficiency. If you try to do it using your regular ways, you will never be able to do anything in time, let alone doing it in real-time. This is where Apache Spark comes into picture. It is an open source big data processing framework that can process massive amounts of data at high speed using cluster computing. Let’s see how we can install it on Ubuntu. Continue reading “How To Install Apache Spark On Ubuntu”
Enabling Tab Autocomplete In Python Shell
 It’s fun to play around with Python. One of its best features is the interactive shell where we can experiment all we want. Let’s say you open up a shell, declare a bunch of variables and want to operate on them. You don’t want to type the full variables names over and over again, right? Also, it’s difficult to remember the full names of all the inbuilt methods and functions as well. Since we are playing around with the same variables and inbuilt functions, it would be nice to have an autocomplete feature that can complete the variable and function names for us. Fortunately, Python provides that nifty little feature! Let’s see how we can enable it here. Continue reading “Enabling Tab Autocomplete In Python Shell”
It’s fun to play around with Python. One of its best features is the interactive shell where we can experiment all we want. Let’s say you open up a shell, declare a bunch of variables and want to operate on them. You don’t want to type the full variables names over and over again, right? Also, it’s difficult to remember the full names of all the inbuilt methods and functions as well. Since we are playing around with the same variables and inbuilt functions, it would be nice to have an autocomplete feature that can complete the variable and function names for us. Fortunately, Python provides that nifty little feature! Let’s see how we can enable it here. Continue reading “Enabling Tab Autocomplete In Python Shell”
Dissecting Bias vs. Variance Tradeoff In Machine Learning
 I was recently working on a machine learning problem when I stumbled upon an interesting question. I wanted to build a machine learning model using a labeled dataset that can classify an unknown image. It’s a classic supervised learning problem! I was not exactly sure how the model would turn out, so I had to experiment with a bunch of things. If I fine tune the machine learning model too much, then it will be very specific to my training data and it won’t generalize well. If I keep it too simple, then it might generalize well but it won’t detect all the underlying patterns in my training data. How do I know if my training data is generic enough? What issues can cause my machine learning model to be sub-optimal? Continue reading “Dissecting Bias vs. Variance Tradeoff In Machine Learning”
I was recently working on a machine learning problem when I stumbled upon an interesting question. I wanted to build a machine learning model using a labeled dataset that can classify an unknown image. It’s a classic supervised learning problem! I was not exactly sure how the model would turn out, so I had to experiment with a bunch of things. If I fine tune the machine learning model too much, then it will be very specific to my training data and it won’t generalize well. If I keep it too simple, then it might generalize well but it won’t detect all the underlying patterns in my training data. How do I know if my training data is generic enough? What issues can cause my machine learning model to be sub-optimal? Continue reading “Dissecting Bias vs. Variance Tradeoff In Machine Learning”
