 If you are hearing the word “perceptron” for the first time, it sounds a lot like a futuristic robot which can perceive things right? Well, that’s not exactly what it means! Perceptron is a machine learning algorithm for supervised classification. It is one of the very first algorithms to be formulated in the field of artificial intelligence. When it first came out, it was very promising. But over the following years, the performance didn’t exactly reach the expectations. It was studied for many years and the theory was modified and extended in a lot of ways. Now, it has become an integral part in the field of artificial neural networks. So what exactly is a perceptron? Where do we use it in real life?
If you are hearing the word “perceptron” for the first time, it sounds a lot like a futuristic robot which can perceive things right? Well, that’s not exactly what it means! Perceptron is a machine learning algorithm for supervised classification. It is one of the very first algorithms to be formulated in the field of artificial intelligence. When it first came out, it was very promising. But over the following years, the performance didn’t exactly reach the expectations. It was studied for many years and the theory was modified and extended in a lot of ways. Now, it has become an integral part in the field of artificial neural networks. So what exactly is a perceptron? Where do we use it in real life?
What is a perceptron?
In one of my earlier blog posts about Artificial Neural Networks, I discussed about neurons and how machines are trying to emulate their functionality. The perceptron is a simple model of a neuron. The formulation of perceptron was the first step towards modeling the human brain and the biological neural network. Perceptrons are simple data structures and they are very easy to learn. A perceptron is a node of a big interconnected network, just like the neurons in the human brain. The links between these nodes show the relationship between the nodes as well as the transmission of data and information.
A perceptron has a number of external input links, one internal input (called bias), a threshold, and one output link. Usually, the input values are boolean (that is, they can only have two possible values: 1 or 0), but they can be any real number as well. The output of the perceptron, however, is always boolean. When the output is on (has the value 1), the perceptron is said to be firing.
Perceptron Learning Theory
The main reason perceptron was formulated was to facilitate artificial intelligence. So how can we achieve learning using a perceptron? We need to train them so they can do things that are useful. To do this, we must allow the neuron to learn from its mistakes. Hence supervised learning is used to achieve our goal. We take the following approach:
- Set the weight and thresholds of the neuron to random values.
- Present an input.
- Calculate the output of the neuron.
- Alter the weights to reinforce correct decisions and discourage wrong decisions, hence reducing the error. This is the supervised part. I have discussed more about this here.
- Now present the next input and repeat steps 3 and 4.
By the end of many iterations, the perceptron would have learnt what’s right and what’s wrong. As we feed more data, the accuracy keeps increasing.
Single layer perceptron
The simplest kind of neural network is a single-layer perceptron network. It consists of a single layer of output nodes. The inputs are fed directly to the outputs through a series of weights. In this way, it can be considered the simplest kind of feed-forward network. The sum of the products of the weights and the inputs is calculated in each node. If the value is above some threshold, the neuron fires and takes the activated value. Otherwise it takes the deactivated value. Single-unit perceptrons are only capable of learning linearly separable patterns. I have discussed more about linear separability here.
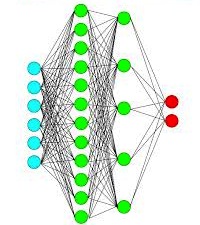
Multi layer perceptron
A single layer perceptron is a very simple model. In real world, things are much more complex. To get closer to what’s actually happening in the brain, we need to extend the single layer perceptron. Hence people came up with multi layer perceptron. A multi layer perceptron is an interconnected network of perceptrons designed to learn and make intelligent decisions automatically. For multilayer perceptrons we use again use a supervised learning rule known as the “back-propagation rule”. This class of networks consists of multiple layers of computational units, usually interconnected in a feed-forward way. Each neuron in one layer has directed connections to the neurons of the subsequent layer.
When we show an input pattern to an untrained network, it produces a random output. Now how will it know how to modify itself to produce the correct outputs? We need to define an error function which represents the difference between the output produced by the network and the output we desire. This error function must be continually reduced so our output reaches that of the desired output.
To achieve this we adjust the weights on the links between layers. This is done by calculating the error for a particular input and back-propagating it through to the previous layer. Thus each unit in the network has its weights adjusted so that it reduces the value of the error function and the network learns.
———————————————————————————————————–

Hi,
I enjoyed reading your articles, specially the things regarding AI! 🙂 but I found this blog while I was in search for something iOS related programming issue, in Google! 🙂
Anyway I hope that you would write more and more regarding these misc of topics but which are important and fascinating stuff including AI, Machine Learning and things and may be practical but yet simple examples of how to program them! 🙂
Thanks! 🙂 (Y)
Thanks a lot 🙂
I try to cover a wide range of topics, but I definitely like writing about machine learning and AI. I will keep your suggestions in mind.