 Let’s say you are given a small set of data points. These data points can take any form like weight distribution of people, location of people who buy your products, types of smartphones, etc. Now your job is to estimate the underlying model. As in, if an unknown point comes in, you should to be able to fit it into your model. Typical supervised learning stuff! But the problem is that you have very few datapoints to begin with. So how do we accurately estimate that model? Should you really tighten your model to satisfy every single point you have?
Let’s say you are given a small set of data points. These data points can take any form like weight distribution of people, location of people who buy your products, types of smartphones, etc. Now your job is to estimate the underlying model. As in, if an unknown point comes in, you should to be able to fit it into your model. Typical supervised learning stuff! But the problem is that you have very few datapoints to begin with. So how do we accurately estimate that model? Should you really tighten your model to satisfy every single point you have?
What is overfitting?
As seen in the image here, you are given a bunch of points. Your job is to come up with that underlying curve.

In machine learning, overfitting occurs when a learning model customizes itself too much to describe the relationship between training data and the labels. Overfitting tends to make the model very complex by having too many parameters. By doing this, it loses its generalization power, which leads to poor performance on new data.
Why does it happen?
The reason this happens is because we use different criteria to train the model and then test its efficiency. As we know, a model is trained by maximizing its accuracy on the training dataset. But its performance is determined on its ability to perform well on unknown data. In this situation, overfitting occurs when our model tries to memorize the training data as opposed to try to generalize from patterns observed in the training data.
For example, let’s say if the number of parameters in our model is greater than the number of datapoints in our training dataset. In this case, a learning model can predict the output for training data by simply memorizing the entire training dataset. But as you can imagine, such model will fail drastically when dealing with unknown data.
How do we solve this issue?
One way to avoid overfitting is to use a lot of data. The main reason overfitting happens is because you have a small dataset and you try to learn from it. The algorithm will have greater control over this small dataset and it will make sure it satisfies all the datapoints exactly. But if you have a large number of datapoints, then the algorithm is forced to generalize and come up with a good model that suits most of the points.
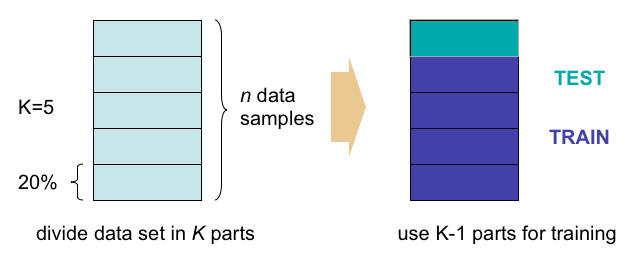
We don’t have the luxury of gathering a large database all the time. Sometimes we are limited to a small database and we are forced to come up with a model based on that. In these situations, we use a technique called cross validation. What it does it that it splits the dataset into training and testing datasets. Only the datapoints in the training dataset are used to come up with the model and the testing dataset is used to test how good the model is. This is repeated with different partitions of training and testing datasets. This method gives a fairly good estimate of the underlying model because we are testing it on different partitions to generalize it as much as possible.
————————————————————————————————-

Reblogged this on #iblogstats and commented:
Over-fitting.. takes me back.. TY
good basic understanding
Thanks 🙂
Very Good Information.