 Even though it has an ornate name, the underlying concept is actually quite simple and intuitive. The concept of Empirical Risk Minimization becomes relevant in the world of supervised learning. The actual goal of supervised learning is to find a model that solves a problem as opposed to finding a model that best fits the given dataset. Since we don’t have every single data point that represents each class completely, we just use the next best thing available, which is a dataset that’s representative of the classes. We can think of the process of supervised learning as choosing a function that achieves a given goal. We have to choose this function from a set of potential functions. Now how can we measure the effectiveness of this chosen function given that we don’t know what the actual distribution looks like? Bear in mind that all the potential functions can achieve the given goal. How do we find the function that’s the best representative of the true solution? Continue reading “What is Empirical Risk Minimization”
Even though it has an ornate name, the underlying concept is actually quite simple and intuitive. The concept of Empirical Risk Minimization becomes relevant in the world of supervised learning. The actual goal of supervised learning is to find a model that solves a problem as opposed to finding a model that best fits the given dataset. Since we don’t have every single data point that represents each class completely, we just use the next best thing available, which is a dataset that’s representative of the classes. We can think of the process of supervised learning as choosing a function that achieves a given goal. We have to choose this function from a set of potential functions. Now how can we measure the effectiveness of this chosen function given that we don’t know what the actual distribution looks like? Bear in mind that all the potential functions can achieve the given goal. How do we find the function that’s the best representative of the true solution? Continue reading “What is Empirical Risk Minimization”
Tag: Supervised Learning
Measuring the Stability of Machine Learning Algorithms
 When you think of a machine learning algorithm, the first metric that comes to mind is its accuracy. A lot of research is centered on developing algorithms that are accurate and can predict the outcome with a high degree of confidence. During the training process, an important issue to think about is the stability of the learning algorithm. This allows us to understand how a particular model is going to turn out. We need to make sure that it generalizes well to various training sets. Estimating the stability becomes crucial in these situations. So what exactly is stability? How do we estimate it? Continue reading “Measuring the Stability of Machine Learning Algorithms”
When you think of a machine learning algorithm, the first metric that comes to mind is its accuracy. A lot of research is centered on developing algorithms that are accurate and can predict the outcome with a high degree of confidence. During the training process, an important issue to think about is the stability of the learning algorithm. This allows us to understand how a particular model is going to turn out. We need to make sure that it generalizes well to various training sets. Estimating the stability becomes crucial in these situations. So what exactly is stability? How do we estimate it? Continue reading “Measuring the Stability of Machine Learning Algorithms”
How To Compute Confidence Measure For SVM Classifiers
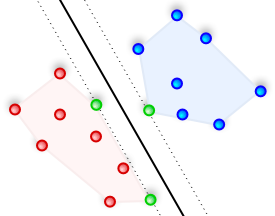 Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
Dissecting Bias vs. Variance Tradeoff In Machine Learning
 I was recently working on a machine learning problem when I stumbled upon an interesting question. I wanted to build a machine learning model using a labeled dataset that can classify an unknown image. It’s a classic supervised learning problem! I was not exactly sure how the model would turn out, so I had to experiment with a bunch of things. If I fine tune the machine learning model too much, then it will be very specific to my training data and it won’t generalize well. If I keep it too simple, then it might generalize well but it won’t detect all the underlying patterns in my training data. How do I know if my training data is generic enough? What issues can cause my machine learning model to be sub-optimal? Continue reading “Dissecting Bias vs. Variance Tradeoff In Machine Learning”
I was recently working on a machine learning problem when I stumbled upon an interesting question. I wanted to build a machine learning model using a labeled dataset that can classify an unknown image. It’s a classic supervised learning problem! I was not exactly sure how the model would turn out, so I had to experiment with a bunch of things. If I fine tune the machine learning model too much, then it will be very specific to my training data and it won’t generalize well. If I keep it too simple, then it might generalize well but it won’t detect all the underlying patterns in my training data. How do I know if my training data is generic enough? What issues can cause my machine learning model to be sub-optimal? Continue reading “Dissecting Bias vs. Variance Tradeoff In Machine Learning”
Overfitting In Machine Learning
 Let’s say you are given a small set of data points. These data points can take any form like weight distribution of people, location of people who buy your products, types of smartphones, etc. Now your job is to estimate the underlying model. As in, if an unknown point comes in, you should to be able to fit it into your model. Typical supervised learning stuff! But the problem is that you have very few datapoints to begin with. So how do we accurately estimate that model? Should you really tighten your model to satisfy every single point you have? Continue reading “Overfitting In Machine Learning”
Let’s say you are given a small set of data points. These data points can take any form like weight distribution of people, location of people who buy your products, types of smartphones, etc. Now your job is to estimate the underlying model. As in, if an unknown point comes in, you should to be able to fit it into your model. Typical supervised learning stuff! But the problem is that you have very few datapoints to begin with. So how do we accurately estimate that model? Should you really tighten your model to satisfy every single point you have? Continue reading “Overfitting In Machine Learning”
Support Vector Machines
 In machine learning, we have supervised learning on one end and unsupervised learning on the other end. Support Vector Machines (SVMs) are supervised learning models used to analyze and classify data. We use machine learning algorithms to train the machines. Once we have a model, we can classify unknown data. Let’s say you have a set of data points and they belong one of the two possible classes. Now our task is to find the best possible way to put a boundary between the two sets of points. When a new point comes in, we can use this boundary to decide whether it belongs to class 1 or class 2. In real life, these data points can be a set of observations like images, text, characters, protein sequences etc. How can we achieve this in the most optimal way? Continue reading “Support Vector Machines”
In machine learning, we have supervised learning on one end and unsupervised learning on the other end. Support Vector Machines (SVMs) are supervised learning models used to analyze and classify data. We use machine learning algorithms to train the machines. Once we have a model, we can classify unknown data. Let’s say you have a set of data points and they belong one of the two possible classes. Now our task is to find the best possible way to put a boundary between the two sets of points. When a new point comes in, we can use this boundary to decide whether it belongs to class 1 or class 2. In real life, these data points can be a set of observations like images, text, characters, protein sequences etc. How can we achieve this in the most optimal way? Continue reading “Support Vector Machines”
