 Let’s say you are a clothes designer and you want to design a pair of jeans. Since you are new to all this, you go out and collect a bunch of measurements from people to see how to design your jeans as far as sizing is concerned. One aspect of this project would be to see how the height of a person relates to the size of the jeans you are designing. From the measurements you took from those people, you notice a certain pattern that relates height of a person to the overall size of the jeans. Now you generalize this pattern and say that for a given height, a particular size is recommended. To deduce the pattern, you just took a bunch of points and drew a line through them so that it is close to all those points. Pretty simple right! What if there are a few points that are way off from all the other points? Would you consider them while deducing your pattern? You will probably discard them because they are outliers. This was a small sample set, so you could notice these outliers manually. What if there were a million points?
Let’s say you are a clothes designer and you want to design a pair of jeans. Since you are new to all this, you go out and collect a bunch of measurements from people to see how to design your jeans as far as sizing is concerned. One aspect of this project would be to see how the height of a person relates to the size of the jeans you are designing. From the measurements you took from those people, you notice a certain pattern that relates height of a person to the overall size of the jeans. Now you generalize this pattern and say that for a given height, a particular size is recommended. To deduce the pattern, you just took a bunch of points and drew a line through them so that it is close to all those points. Pretty simple right! What if there are a few points that are way off from all the other points? Would you consider them while deducing your pattern? You will probably discard them because they are outliers. This was a small sample set, so you could notice these outliers manually. What if there were a million points?
Why do we need RANSAC?
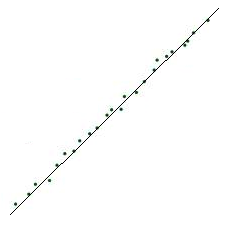 RANSAC stands for RANdom Sample Consensus. When you ask a computer to deduce a pattern, it will look at all the input data points and come up with a model that will fit all these points well. As seen in the figure, the line passes through all the points. The metric used to see how good the line fits the model is called least squares method. You just compute the perpendicular distance of each point from the line and see which line gives the least error. Nice and simple!
RANSAC stands for RANdom Sample Consensus. When you ask a computer to deduce a pattern, it will look at all the input data points and come up with a model that will fit all these points well. As seen in the figure, the line passes through all the points. The metric used to see how good the line fits the model is called least squares method. You just compute the perpendicular distance of each point from the line and see which line gives the least error. Nice and simple!

 Consider the figure on the left. Now if we use the same method for the set of points shown here, this is the line you get. It’s not exactly close to the points right? This happened because it tried to fit those five points that are far off from the rest. In reality, they are outliers and shouldn’t be considered while modeling. The regular method was not able to detect it. The figure on the right indicates the line detected by RANSAC. This is the reason we need RANSAC. In fact, it is used widely in the field of computer vision to model a lot of things.
Consider the figure on the left. Now if we use the same method for the set of points shown here, this is the line you get. It’s not exactly close to the points right? This happened because it tried to fit those five points that are far off from the rest. In reality, they are outliers and shouldn’t be considered while modeling. The regular method was not able to detect it. The figure on the right indicates the line detected by RANSAC. This is the reason we need RANSAC. In fact, it is used widely in the field of computer vision to model a lot of things.
What is RANSAC?
The RANSAC algorithm is a general approach designed to cope with a large proportion of outliers in the input data. Unlike many of the common robust estimation techniques that have been adopted by the computer vision community (mostly from the field of mathematics), RANSAC was actually developed from within the computer vision community. As it so happens, computer vision problems encounter outliers very frequently. RANSAC is a resampling technique that generates candidate solutions by using the minimum number of observations (data points) required to estimate the underlying model parameters. Unlike conventional sampling techniques that use as much of the data as possible to obtain an initial solution and then proceed to prune outliers, RANSAC uses the smallest set possible and proceeds to enlarge this set with consistent data points.
How does RANSAC do it?
The algorithm can be summarized as given below:
- Select randomly the minimum number of points required to determine the model parameters. Determining the model parameters refers to deducing the pattern in our example.
- Solve for the parameters of the model. This refers to the formula that relates the height of people with the size of the jeans.
- Determine how many points from the set of all points fit with a predefined tolerance. This refers to you getting the formula and applying it to other people to see if it gives correct sizes.
- If the fraction of the number of inliers over the total number points in the set exceeds a predefined threshold, re-estimate the model parameters using all the identified inliers and terminate. This step corresponds to the fact that if too many people get wrong sizes using your formula, you know that there is something wrong with the formula.
- Otherwise, repeat steps 1 through 4 (maximum of N times).
————————————————————————————————-

Great post. Love your blog. Keep posting.
Cheers!
Good to know. Thanks!