 This is a continuation of my previous blog post on image classification and the bag of words (BoW) model. If you already know how BoW works, then you will feel right at home. If you need a refresher, you can read the blog post here. In our previous post, we discussed how BoW works, and how we construct the codebook. An interesting thing to note is that we don’t consider how things are ordered as such. A given image is treated as a combination of codewords regardless of where they are located with respect to each other. If we want to improve the performance of BoW, we can definitely increase the size of the vocabulary. If we have more codewords, we can describe a given image better. But what if we don’t want to do that? Is there a more efficient method that can be used? Continue reading “Image Classification Using Fisher Vectors”
This is a continuation of my previous blog post on image classification and the bag of words (BoW) model. If you already know how BoW works, then you will feel right at home. If you need a refresher, you can read the blog post here. In our previous post, we discussed how BoW works, and how we construct the codebook. An interesting thing to note is that we don’t consider how things are ordered as such. A given image is treated as a combination of codewords regardless of where they are located with respect to each other. If we want to improve the performance of BoW, we can definitely increase the size of the vocabulary. If we have more codewords, we can describe a given image better. But what if we don’t want to do that? Is there a more efficient method that can be used? Continue reading “Image Classification Using Fisher Vectors”
Tag: Images
Image Classification Using Bag-Of-Words Model
 Image classification is one of the classical problems in computer vision. Basically, the goal is to determine whether or not the given image contains a particular thing like an object or a person. Humans tend to classify images effortlessly, but machines seem to have a hard time doing this. Computer Vision has achieved some success in the case of specific problems, like detecting faces in an image. But it has still not satisfactorily solved the problem for the general case where we have random objects in different positions and orientations. Bag-of-words (BoW) model is one of the most popular approaches in this field, and many modern approaches are based on top of this. So what exactly is it? Continue reading “Image Classification Using Bag-Of-Words Model”
Image classification is one of the classical problems in computer vision. Basically, the goal is to determine whether or not the given image contains a particular thing like an object or a person. Humans tend to classify images effortlessly, but machines seem to have a hard time doing this. Computer Vision has achieved some success in the case of specific problems, like detecting faces in an image. But it has still not satisfactorily solved the problem for the general case where we have random objects in different positions and orientations. Bag-of-words (BoW) model is one of the most popular approaches in this field, and many modern approaches are based on top of this. So what exactly is it? Continue reading “Image Classification Using Bag-Of-Words Model”
The Concept Of Homogeneous Coordinates
 People in computer vision and graphics deal with homogeneous coordinates on a very regular basis. They are actually a nice extension of standard three dimensional vectors and allow us to simplify various transforms and their computations. When I say “transformations”, I am talking about all those special effects on the screen, and the corresponding movements and scaling of various objects. But why do we need homogeneous coordinates to do all that? Why can’t we just move the objects around? Well, we can’t directly do that, not easily anyway! This will become clear soon. The concept of homogeneous coordinates is fundamental when we talk about cameras. In order to design our algorithms, we need to understand how the cameras are looking at the real world. This is in fact utilized heavily by game programmers as well. So what is it all about? Why is it so important? Continue reading “The Concept Of Homogeneous Coordinates”
People in computer vision and graphics deal with homogeneous coordinates on a very regular basis. They are actually a nice extension of standard three dimensional vectors and allow us to simplify various transforms and their computations. When I say “transformations”, I am talking about all those special effects on the screen, and the corresponding movements and scaling of various objects. But why do we need homogeneous coordinates to do all that? Why can’t we just move the objects around? Well, we can’t directly do that, not easily anyway! This will become clear soon. The concept of homogeneous coordinates is fundamental when we talk about cameras. In order to design our algorithms, we need to understand how the cameras are looking at the real world. This is in fact utilized heavily by game programmers as well. So what is it all about? Why is it so important? Continue reading “The Concept Of Homogeneous Coordinates”
Understanding Camera Calibration
 Cameras have been around for a long time now. When cameras were first introduced, they were expensive and you needed a good amount of money to own one. However, people then came up with pinhole cameras in the late 20th century. These cameras were inexpensive and they became a common occurrence in our everyday life. Unfortunately, as is the case with any trade off, this convenience comes at a price. These pinhole cameras have significant distortion! The good thing is that these distortions are constant and they can be corrected. This is where camera calibration comes into picture. So what is this all about? How can we deal with this distortion? Continue reading “Understanding Camera Calibration”
Cameras have been around for a long time now. When cameras were first introduced, they were expensive and you needed a good amount of money to own one. However, people then came up with pinhole cameras in the late 20th century. These cameras were inexpensive and they became a common occurrence in our everyday life. Unfortunately, as is the case with any trade off, this convenience comes at a price. These pinhole cameras have significant distortion! The good thing is that these distortions are constant and they can be corrected. This is where camera calibration comes into picture. So what is this all about? How can we deal with this distortion? Continue reading “Understanding Camera Calibration”
What Is Gamma Correction?
 Gamma correction is an integral part of all the digital imaging systems, but a lot of people don’t know about it! It is an essential part of all the imaging devices like cameras, camcorders, monitors, video players, etc. It basically defines the relationship between a pixel’s numerical value and its actual luminance. Now wait a minute, why would they be different? Isn’t a pixel’s numerical value supposed to be exactly the same as its luminance? Well, not really! Without gamma, shades captured by digital cameras wouldn’t appear as they did to our eyes. If we fully understand how gamma works, we can improve our exposure technique, along with making the most of image editing. So what is it all about? Why do we need gamma correction at all? Continue reading “What Is Gamma Correction?”
Gamma correction is an integral part of all the digital imaging systems, but a lot of people don’t know about it! It is an essential part of all the imaging devices like cameras, camcorders, monitors, video players, etc. It basically defines the relationship between a pixel’s numerical value and its actual luminance. Now wait a minute, why would they be different? Isn’t a pixel’s numerical value supposed to be exactly the same as its luminance? Well, not really! Without gamma, shades captured by digital cameras wouldn’t appear as they did to our eyes. If we fully understand how gamma works, we can improve our exposure technique, along with making the most of image editing. So what is it all about? Why do we need gamma correction at all? Continue reading “What Is Gamma Correction?”
Recognizing Shapes Using Point Distribution Models
 In the field of computer vision, we often come across situations where we need to recognize the shapes of different objects. Not only that, we also need our machines to understand the shapes so that we can identify them even if we encounter them in different forms. Humans are really good at these things. We somehow make a mental note about these shapes and create a mapping in our brain. But if somebody asks you to write a formula or a function to identify it, we cannot come up with a precise set of rules. In fact, the whole field of computer vision is based on chasing this hold grail. In this blog post, we will discuss a particular model which is used to identify different shapes. Continue reading “Recognizing Shapes Using Point Distribution Models”
In the field of computer vision, we often come across situations where we need to recognize the shapes of different objects. Not only that, we also need our machines to understand the shapes so that we can identify them even if we encounter them in different forms. Humans are really good at these things. We somehow make a mental note about these shapes and create a mapping in our brain. But if somebody asks you to write a formula or a function to identify it, we cannot come up with a precise set of rules. In fact, the whole field of computer vision is based on chasing this hold grail. In this blog post, we will discuss a particular model which is used to identify different shapes. Continue reading “Recognizing Shapes Using Point Distribution Models”
Understanding Gabor Filters
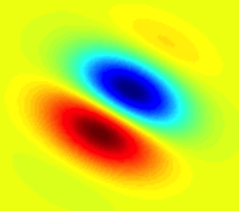 In the field of image processing, filters play an extremely important role. If you don’t know what a filter is, you may quickly want to read the wiki article and come back. Otherwise, this post will not make much sense to you. All image processing operations can be viewed as applying a series of filters to an image and transforming it in some way. We do this for a variety of reasons, like understanding the content of images, transforming the images into another domain, detecting the presence of something in the images, and so on. Gabor filter is a particular type of filter, and it happens to be an important one. If you google “Gabor filter”, you will get a lot of articles. So in this post, rather than looking at the mathematics behind it, we will try to understand the underlying concept. Let’s go ahead, shall we? Continue reading “Understanding Gabor Filters”
In the field of image processing, filters play an extremely important role. If you don’t know what a filter is, you may quickly want to read the wiki article and come back. Otherwise, this post will not make much sense to you. All image processing operations can be viewed as applying a series of filters to an image and transforming it in some way. We do this for a variety of reasons, like understanding the content of images, transforming the images into another domain, detecting the presence of something in the images, and so on. Gabor filter is a particular type of filter, and it happens to be an important one. If you google “Gabor filter”, you will get a lot of articles. So in this post, rather than looking at the mathematics behind it, we will try to understand the underlying concept. Let’s go ahead, shall we? Continue reading “Understanding Gabor Filters”
How To Install PIL On Ubuntu
 Let’s say you want to play around with images in Python. To do that, we need a Python package that can handle all the image manipulation. Python Imaging Library (PIL) is one of most popular libraries that is used to process the image data. Actually, people use Pillow now, which is a modern repackaged version of PIL. It has a lot of nice functionalities and it works well. Let’s see how you can install PIL on 64-bit Ubuntu 12.04. Continue reading “How To Install PIL On Ubuntu”
Let’s say you want to play around with images in Python. To do that, we need a Python package that can handle all the image manipulation. Python Imaging Library (PIL) is one of most popular libraries that is used to process the image data. Actually, people use Pillow now, which is a modern repackaged version of PIL. It has a lot of nice functionalities and it works well. Let’s see how you can install PIL on 64-bit Ubuntu 12.04. Continue reading “How To Install PIL On Ubuntu”
How To Take A Screenshot On Mac OS X
 One of the many good things about Mac OS X is the built in support for taking screenshots. But then again, in this day and age, what operating system doesn’t? Well, this is where it differs a little. I am sure most of you know how to capture a screenshot on OS X, but there might be situations where your requirements change a bit. There are many different ways to capture the content being displayed on your screen. Each one of those methods has something different and unique to offer. These methods are very handy at times! I have described a few different methods here. Let’s see what they are. Continue reading “How To Take A Screenshot On Mac OS X”
One of the many good things about Mac OS X is the built in support for taking screenshots. But then again, in this day and age, what operating system doesn’t? Well, this is where it differs a little. I am sure most of you know how to capture a screenshot on OS X, but there might be situations where your requirements change a bit. There are many different ways to capture the content being displayed on your screen. Each one of those methods has something different and unique to offer. These methods are very handy at times! I have described a few different methods here. Let’s see what they are. Continue reading “How To Take A Screenshot On Mac OS X”
Reading JPEG Into A Byte Array
Let’s say you are work ing with images for your project. A lot of times, when you have to work across multiple platforms, the encoding doesn’t remain the same. In these scenarios, you cannot process images directly by treating them like 2D matrices. One of the most common image formats you will comes across is JPEG. If you are working on the same platform using a library like OpenCV, you can directly read JPEG files into 2D data structures. If not, you will have to read it into a byte array, process it and then encode it back. How do we do that? Continue reading “Reading JPEG Into A Byte Array”
ing with images for your project. A lot of times, when you have to work across multiple platforms, the encoding doesn’t remain the same. In these scenarios, you cannot process images directly by treating them like 2D matrices. One of the most common image formats you will comes across is JPEG. If you are working on the same platform using a library like OpenCV, you can directly read JPEG files into 2D data structures. If not, you will have to read it into a byte array, process it and then encode it back. How do we do that? Continue reading “Reading JPEG Into A Byte Array”
