If you have fiddled around enough with C/C++/Objective-C, you must have noticed that if you use rand() function on its own, it gives the exact same numbers every time. Now how is that possible? Isn’t rand() function supposed to generated completely random numbers in a given range? The reason for this has something to do with the seed value. If you use the same seed value every time, then you will get the same numbers. Continue reading “Random Number Generators In Programming”
Tag: Probability
Gaussian Mixture Models
 Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this? Continue reading “Gaussian Mixture Models”
Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this? Continue reading “Gaussian Mixture Models”
What Are Conditional Random Fields?
 This is a continuation of my previous blog post. In that post, we discussed about why we need conditional random fields in the first place. We have graphical models in machine learning that are widely used to solve many different problems. But Conditional Random Fields (CRFs) address a critical problem faced by these graphical models. A popular example for graphical models is Hidden Markov Models (HMMs). HMMs have gained a lot of popularity in recent years due to their robustness and accuracy. They are used in computer vision, speech recognition and other time-series related data analysis. CRFs outperform HMMs in many different tasks. How is that? What are these CRFs and how are they formulated? Continue reading “What Are Conditional Random Fields?”
This is a continuation of my previous blog post. In that post, we discussed about why we need conditional random fields in the first place. We have graphical models in machine learning that are widely used to solve many different problems. But Conditional Random Fields (CRFs) address a critical problem faced by these graphical models. A popular example for graphical models is Hidden Markov Models (HMMs). HMMs have gained a lot of popularity in recent years due to their robustness and accuracy. They are used in computer vision, speech recognition and other time-series related data analysis. CRFs outperform HMMs in many different tasks. How is that? What are these CRFs and how are they formulated? Continue reading “What Are Conditional Random Fields?”
Why Do We Need Conditional Random Fields?
 This is a two-part discussion. In this blog post, we will discuss the need for conditional random fields. In the next one, we will discuss what exactly they are and how do we use them. The task of assigning labels to a set of observation sequences arises in many fields, including computer vision, bioinformatics, computational linguistics and speech recognition. For example, consider the natural language processing task of labeling the words in a sentence with their corresponding part-of-speech tags. In this task, each word is labeled with a tag indicating its appropriate part of speech, resulting in annotated text. To give another example, consider the task of labeling a video with the mental state of a person based on the observed behavior. You have to analyze the facial expressions of the user and determine if the user is happy, angry, sad etc. We often wish to predict a large number of variables that depend on each other as well as on other observed variables. How to achieve these tasks? What model should we use? Continue reading “Why Do We Need Conditional Random Fields?”
This is a two-part discussion. In this blog post, we will discuss the need for conditional random fields. In the next one, we will discuss what exactly they are and how do we use them. The task of assigning labels to a set of observation sequences arises in many fields, including computer vision, bioinformatics, computational linguistics and speech recognition. For example, consider the natural language processing task of labeling the words in a sentence with their corresponding part-of-speech tags. In this task, each word is labeled with a tag indicating its appropriate part of speech, resulting in annotated text. To give another example, consider the task of labeling a video with the mental state of a person based on the observed behavior. You have to analyze the facial expressions of the user and determine if the user is happy, angry, sad etc. We often wish to predict a large number of variables that depend on each other as well as on other observed variables. How to achieve these tasks? What model should we use? Continue reading “Why Do We Need Conditional Random Fields?”
Asymmetric Dominance Effect
 Let’s consider a situation. There is a company with two products, A and B. Both these products have their own merits and demerits. Product A has relatively less features, but it’s price is low. Product B, on the other hand, has more features but it’s more expensive. Consumers tend to pick both these products depending on their needs. Now the company introduces a third product, C. The asymmetric dominance theory says that you can affect the consumer behavior using this third product. You can make the consumers shift towards product A or product B by designing product C in different ways. Now how is that possible? How can we change consumer preference between A and B without even modifying these products? Continue reading “Asymmetric Dominance Effect”
Let’s consider a situation. There is a company with two products, A and B. Both these products have their own merits and demerits. Product A has relatively less features, but it’s price is low. Product B, on the other hand, has more features but it’s more expensive. Consumers tend to pick both these products depending on their needs. Now the company introduces a third product, C. The asymmetric dominance theory says that you can affect the consumer behavior using this third product. You can make the consumers shift towards product A or product B by designing product C in different ways. Now how is that possible? How can we change consumer preference between A and B without even modifying these products? Continue reading “Asymmetric Dominance Effect”
Expectation Maximization
 Probabilistic models are commonly used to model various forms of data, including physical, biological, seismic, etc. Much of their popularity can be attributed to the existence of efficient and robust procedures for learning parameters from observations. Often, however, the only data available for training a probabilistic model are incomplete. Missing values can occur which will not be sufficient to get the model. For example, in medical diagnosis, patient histories generally include results from a limited battery of tests. In gene expression clustering, incomplete data arise from the intentional omission of gene-to-cluster assignments in the probabilistic model. If we use regular techniques to estimate the underlying model, then we will get a wrong estimate. What do we do in these situations? Continue reading “Expectation Maximization”
Probabilistic models are commonly used to model various forms of data, including physical, biological, seismic, etc. Much of their popularity can be attributed to the existence of efficient and robust procedures for learning parameters from observations. Often, however, the only data available for training a probabilistic model are incomplete. Missing values can occur which will not be sufficient to get the model. For example, in medical diagnosis, patient histories generally include results from a limited battery of tests. In gene expression clustering, incomplete data arise from the intentional omission of gene-to-cluster assignments in the probabilistic model. If we use regular techniques to estimate the underlying model, then we will get a wrong estimate. What do we do in these situations? Continue reading “Expectation Maximization”
Bayesian Classifier
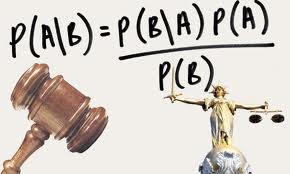 In machine learning, classification is the process of identifying the category of an unknown input based on the set of categories we already have. A classifier, as the name suggests, classifies things into multiple categories. It is used in various real life situations like face detection, image search, fingerprint recognition, etc. Some of the tasks are really simple and a machine can identify the class with absolute certainty. A common example would be to determine if a given number is even or odd. Pretty simple right! But most of the real life problems are not this simple and there is absolutely no way a machine can identify it with absolute certainty. For example, object recognition, weather prediction, handwriting analysis etc. So how do machines deal with these problems? What approach can be used here? Continue reading “Bayesian Classifier”
In machine learning, classification is the process of identifying the category of an unknown input based on the set of categories we already have. A classifier, as the name suggests, classifies things into multiple categories. It is used in various real life situations like face detection, image search, fingerprint recognition, etc. Some of the tasks are really simple and a machine can identify the class with absolute certainty. A common example would be to determine if a given number is even or odd. Pretty simple right! But most of the real life problems are not this simple and there is absolutely no way a machine can identify it with absolute certainty. For example, object recognition, weather prediction, handwriting analysis etc. So how do machines deal with these problems? What approach can be used here? Continue reading “Bayesian Classifier”
The Butterfly Effect
 This blog post is a continuation of my previous post on Chaos Theory. Although it is not required for you to read that post to understand this post, it would be better if you glance through it once. All of us have heard about the Butterfly Effect. It is one of the very famous examples given in the field of chaos theory. I should also give credit to the movie “The Butterfly Effect” for popularizing this term. So what exactly is butterfly effect? Is it just a theory? Where does it happen in real life? Continue reading “The Butterfly Effect”
This blog post is a continuation of my previous post on Chaos Theory. Although it is not required for you to read that post to understand this post, it would be better if you glance through it once. All of us have heard about the Butterfly Effect. It is one of the very famous examples given in the field of chaos theory. I should also give credit to the movie “The Butterfly Effect” for popularizing this term. So what exactly is butterfly effect? Is it just a theory? Where does it happen in real life? Continue reading “The Butterfly Effect”
Chaos Theory
 Chaos Theory is a mathematical sub-discipline that attempts to explain the fact that complex and unpredictable results can and will occur in systems that are sensitive to their initial conditions. Some common examples of systems that chaos theory helped understand are earth’s weather system, the behavior of water boiling on a stove, migratory patterns of birds, or the spread of vegetation across a continent. The Butterfly Effect is one of more famous examples of chaos theory. I have discussed more about it here. Chaos occurs in nature and it manifests itself in various forms. Chaos-based graphics show up all the time, wherever flocks of little space ships sweep across the movie screen in highly complex ways, or whenever amazing landscapes are displayed in some dramatic movie scene. It is used a lot in movies to generate obscure background using computer-generated chaos art. So what exactly is chaos? How does it work? Continue reading “Chaos Theory”
Chaos Theory is a mathematical sub-discipline that attempts to explain the fact that complex and unpredictable results can and will occur in systems that are sensitive to their initial conditions. Some common examples of systems that chaos theory helped understand are earth’s weather system, the behavior of water boiling on a stove, migratory patterns of birds, or the spread of vegetation across a continent. The Butterfly Effect is one of more famous examples of chaos theory. I have discussed more about it here. Chaos occurs in nature and it manifests itself in various forms. Chaos-based graphics show up all the time, wherever flocks of little space ships sweep across the movie screen in highly complex ways, or whenever amazing landscapes are displayed in some dramatic movie scene. It is used a lot in movies to generate obscure background using computer-generated chaos art. So what exactly is chaos? How does it work? Continue reading “Chaos Theory”
Probabilistic Randomness Of Stochasticity
 Do you see what I did with the title there? Anyway, you must have heard the term ‘probability’ being used around you. People use it in different contexts and in different forms – “What is the probability that Spain will win the next world cup?” or “I will probably finish reading the book by midnight” or “It’s quite probable that she won’t return until tomorrow”. When people talk about probability as a mathematical concept, all they think of is the percentage chance of something happening. But is that all there is to it? If that is the case, then why did they have to dedicate an entire branch of study to this? Probability theory is much more than just calculating the likeliness of something happening. It’s used almost everywhere, by almost everyone, for almost everything. Surprised? Well let’s find out then. Continue reading “Probabilistic Randomness Of Stochasticity”
Do you see what I did with the title there? Anyway, you must have heard the term ‘probability’ being used around you. People use it in different contexts and in different forms – “What is the probability that Spain will win the next world cup?” or “I will probably finish reading the book by midnight” or “It’s quite probable that she won’t return until tomorrow”. When people talk about probability as a mathematical concept, all they think of is the percentage chance of something happening. But is that all there is to it? If that is the case, then why did they have to dedicate an entire branch of study to this? Probability theory is much more than just calculating the likeliness of something happening. It’s used almost everywhere, by almost everyone, for almost everything. Surprised? Well let’s find out then. Continue reading “Probabilistic Randomness Of Stochasticity”
