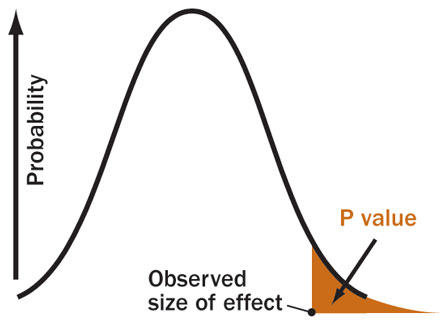
 Let’s say you are a part of the sub-atomic physics team and you are working on discovering an important effect. The thing about sub-atomic physics is that nothing is certain and you cannot say something has happened with 100% certainty. The best we can do is to say that we are x-percent sure that something interesting happened. One fine day, you see some pattern in your data which looks pretty much like what that effect would look like. Now the problem is, your experiment produced data with a lot of noise. People are therefore skeptical of you, and think that the supposed “effect” you claimed to see might just have been a funny pattern in some random noise. How would you convince them that it’s not? Before that, how do you convince yourself that it’s not just noise? A good strategy for arguing your point would be to say, “Alright listen, suppose you’re right, and the patterns in my data really are in fact just from random noise, then how would you explain the fact that random noise very rarely produces patterns like this?”. Pretty good strategy right? Now how do we formulate this mathematically? Continue reading “What Are P-Values?”
Let’s say you are a part of the sub-atomic physics team and you are working on discovering an important effect. The thing about sub-atomic physics is that nothing is certain and you cannot say something has happened with 100% certainty. The best we can do is to say that we are x-percent sure that something interesting happened. One fine day, you see some pattern in your data which looks pretty much like what that effect would look like. Now the problem is, your experiment produced data with a lot of noise. People are therefore skeptical of you, and think that the supposed “effect” you claimed to see might just have been a funny pattern in some random noise. How would you convince them that it’s not? Before that, how do you convince yourself that it’s not just noise? A good strategy for arguing your point would be to say, “Alright listen, suppose you’re right, and the patterns in my data really are in fact just from random noise, then how would you explain the fact that random noise very rarely produces patterns like this?”. Pretty good strategy right? Now how do we formulate this mathematically? Continue reading “What Are P-Values?”
Tag: Statistics
Gaussian Mixture Models
 Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this? Continue reading “Gaussian Mixture Models”
Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this? Continue reading “Gaussian Mixture Models”
Overfitting In Machine Learning
 Let’s say you are given a small set of data points. These data points can take any form like weight distribution of people, location of people who buy your products, types of smartphones, etc. Now your job is to estimate the underlying model. As in, if an unknown point comes in, you should to be able to fit it into your model. Typical supervised learning stuff! But the problem is that you have very few datapoints to begin with. So how do we accurately estimate that model? Should you really tighten your model to satisfy every single point you have? Continue reading “Overfitting In Machine Learning”
Let’s say you are given a small set of data points. These data points can take any form like weight distribution of people, location of people who buy your products, types of smartphones, etc. Now your job is to estimate the underlying model. As in, if an unknown point comes in, you should to be able to fit it into your model. Typical supervised learning stuff! But the problem is that you have very few datapoints to begin with. So how do we accurately estimate that model? Should you really tighten your model to satisfy every single point you have? Continue reading “Overfitting In Machine Learning”
Bayesian Classifier
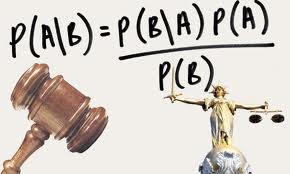 In machine learning, classification is the process of identifying the category of an unknown input based on the set of categories we already have. A classifier, as the name suggests, classifies things into multiple categories. It is used in various real life situations like face detection, image search, fingerprint recognition, etc. Some of the tasks are really simple and a machine can identify the class with absolute certainty. A common example would be to determine if a given number is even or odd. Pretty simple right! But most of the real life problems are not this simple and there is absolutely no way a machine can identify it with absolute certainty. For example, object recognition, weather prediction, handwriting analysis etc. So how do machines deal with these problems? What approach can be used here? Continue reading “Bayesian Classifier”
In machine learning, classification is the process of identifying the category of an unknown input based on the set of categories we already have. A classifier, as the name suggests, classifies things into multiple categories. It is used in various real life situations like face detection, image search, fingerprint recognition, etc. Some of the tasks are really simple and a machine can identify the class with absolute certainty. A common example would be to determine if a given number is even or odd. Pretty simple right! But most of the real life problems are not this simple and there is absolutely no way a machine can identify it with absolute certainty. For example, object recognition, weather prediction, handwriting analysis etc. So how do machines deal with these problems? What approach can be used here? Continue reading “Bayesian Classifier”
The Power Of A/B
 Designing a website is more of an art than a science. There are a million different ways to design a website and achieve a particular goal. We want our websites to eventually become popular and make money. Once the site is designed, it cannot be stagnant for long either. But how do we know if the users will like the new design? User base is critical and losing them is very risky. Once the users lose trust, it’s very difficult to earn it back. We want to take the guesswork out of website optimization and enable making decisions based on real data. By measuring the impact of the changes, you can ensure that every change produces positive results. So how do we do it? Continue reading “The Power Of A/B”
Designing a website is more of an art than a science. There are a million different ways to design a website and achieve a particular goal. We want our websites to eventually become popular and make money. Once the site is designed, it cannot be stagnant for long either. But how do we know if the users will like the new design? User base is critical and losing them is very risky. Once the users lose trust, it’s very difficult to earn it back. We want to take the guesswork out of website optimization and enable making decisions based on real data. By measuring the impact of the changes, you can ensure that every change produces positive results. So how do we do it? Continue reading “The Power Of A/B”
