 Caffe is one the most popular deep learning packages out there. In one of the previous blog posts, we talked about how to install Caffe. In this blog post, we will discuss how to get started with Caffe and use its various features. We will then build a convolutional neural network (CNN) that can be used for image classification. Caffe plays very well with the GPU during the training process, hence we can achieve a lot of speed-up. For the purpose of this discussion, it is assumed that you have already installed Caffe on your machine. Let’s go ahead and see how to interact with Caffe, shall we? Continue reading “Deep Learning With Caffe In Python – Part I: Defining A Layer”
Caffe is one the most popular deep learning packages out there. In one of the previous blog posts, we talked about how to install Caffe. In this blog post, we will discuss how to get started with Caffe and use its various features. We will then build a convolutional neural network (CNN) that can be used for image classification. Caffe plays very well with the GPU during the training process, hence we can achieve a lot of speed-up. For the purpose of this discussion, it is assumed that you have already installed Caffe on your machine. Let’s go ahead and see how to interact with Caffe, shall we? Continue reading “Deep Learning With Caffe In Python – Part I: Defining A Layer”
Category: Machine Learning
How To Train A Neural Network In Python – Part III
 In the previous blog post, we learnt how to build a multilayer neural network in Python. What we did there falls under the category of supervised learning. In that realm, we have some training data and we have the associated labels. Now the goal is to train the neural network correctly label our training data. Once we train the model, we can use it to predict the labels of unknown datapoints. But what about unsupervised learning? In the real world, we also have to deal with a lot of unlabeled data. Can we train a neural network to recognize clusters in our data? Yes, we certainly can! Let’s go ahead and see how we can do that in Python, shall we? Continue reading “How To Train A Neural Network In Python – Part III”
In the previous blog post, we learnt how to build a multilayer neural network in Python. What we did there falls under the category of supervised learning. In that realm, we have some training data and we have the associated labels. Now the goal is to train the neural network correctly label our training data. Once we train the model, we can use it to predict the labels of unknown datapoints. But what about unsupervised learning? In the real world, we also have to deal with a lot of unlabeled data. Can we train a neural network to recognize clusters in our data? Yes, we certainly can! Let’s go ahead and see how we can do that in Python, shall we? Continue reading “How To Train A Neural Network In Python – Part III”
How To Train A Neural Network In Python – Part II
 In the previous blog post, we discussed about perceptrons. We learnt how to train a perceptron in Python to achieve a simple classification task. If you need a quick refresher on perceptrons, you can check out that blog post before proceeding further. In a way, perceptron is a single layer neural network with a single neuron. In this blog post, we will learn how to develop a multilayer neural network. A multilayer neural network consists of multiple layers and each layer consists of many perceptrons, and it is much better at classifying data that a single perceptron. So how exactly does a multilayer neural network function? How do we build it in Python? Continue reading “How To Train A Neural Network In Python – Part II”
In the previous blog post, we discussed about perceptrons. We learnt how to train a perceptron in Python to achieve a simple classification task. If you need a quick refresher on perceptrons, you can check out that blog post before proceeding further. In a way, perceptron is a single layer neural network with a single neuron. In this blog post, we will learn how to develop a multilayer neural network. A multilayer neural network consists of multiple layers and each layer consists of many perceptrons, and it is much better at classifying data that a single perceptron. So how exactly does a multilayer neural network function? How do we build it in Python? Continue reading “How To Train A Neural Network In Python – Part II”
How To Train A Neural Network In Python – Part I
 Deep learning uses neural networks to build sophisticated models. The basic building blocks of these neural networks are called “neurons”. When a neuron is trained to act like a simple classifier, we call it “perceptron”. A neural network consists of a lot of perceptrons interconnected with each other. Let’s say we have a bunch of inputs and the corresponding desired outputs. The goal of deep learning is to train this neural network so that the system outputs the right value for the given set of inputs. This process basically involves tuning each neuron in the network until it behaves a certain way. So what exactly is this perceptron? How do we train it in Python? Continue reading “How To Train A Neural Network In Python – Part I”
Deep learning uses neural networks to build sophisticated models. The basic building blocks of these neural networks are called “neurons”. When a neuron is trained to act like a simple classifier, we call it “perceptron”. A neural network consists of a lot of perceptrons interconnected with each other. Let’s say we have a bunch of inputs and the corresponding desired outputs. The goal of deep learning is to train this neural network so that the system outputs the right value for the given set of inputs. This process basically involves tuning each neuron in the network until it behaves a certain way. So what exactly is this perceptron? How do we train it in Python? Continue reading “How To Train A Neural Network In Python – Part I”
How To Install Caffe On Ubuntu
 The concept of deep learning is becoming increasingly pervasive. It is a new area of research in machine learning that focuses on learning optimal representations of data. Now what does it mean? In the realm of classical machine learning, we have the build the features first and then the machine learning algorithm will learn how to classify the data based on these features. The problem is that feature-building is a trial-and-error process and we want to avoid manual intervention. This is where deep learning tends to shine! Instead of manually building the features ourselves, we can just let our deep neural networks learn the features and then build a system to classify that data. In this field, people work towards building a set of algorithms that can model abstractions in our data using multilayered neural networks. Caffe is one of the most popular libraries available out there for deep learning. Let’s go ahead and see how to get it up and running on Ubuntu, shall we? Continue reading “How To Install Caffe On Ubuntu”
The concept of deep learning is becoming increasingly pervasive. It is a new area of research in machine learning that focuses on learning optimal representations of data. Now what does it mean? In the realm of classical machine learning, we have the build the features first and then the machine learning algorithm will learn how to classify the data based on these features. The problem is that feature-building is a trial-and-error process and we want to avoid manual intervention. This is where deep learning tends to shine! Instead of manually building the features ourselves, we can just let our deep neural networks learn the features and then build a system to classify that data. In this field, people work towards building a set of algorithms that can model abstractions in our data using multilayered neural networks. Caffe is one of the most popular libraries available out there for deep learning. Let’s go ahead and see how to get it up and running on Ubuntu, shall we? Continue reading “How To Install Caffe On Ubuntu”
How To Compute Confidence Measure For SVM Classifiers
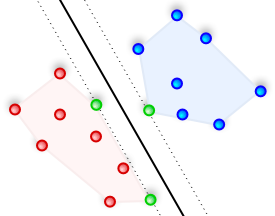 Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
Dissecting Bias vs. Variance Tradeoff In Machine Learning
 I was recently working on a machine learning problem when I stumbled upon an interesting question. I wanted to build a machine learning model using a labeled dataset that can classify an unknown image. It’s a classic supervised learning problem! I was not exactly sure how the model would turn out, so I had to experiment with a bunch of things. If I fine tune the machine learning model too much, then it will be very specific to my training data and it won’t generalize well. If I keep it too simple, then it might generalize well but it won’t detect all the underlying patterns in my training data. How do I know if my training data is generic enough? What issues can cause my machine learning model to be sub-optimal? Continue reading “Dissecting Bias vs. Variance Tradeoff In Machine Learning”
I was recently working on a machine learning problem when I stumbled upon an interesting question. I wanted to build a machine learning model using a labeled dataset that can classify an unknown image. It’s a classic supervised learning problem! I was not exactly sure how the model would turn out, so I had to experiment with a bunch of things. If I fine tune the machine learning model too much, then it will be very specific to my training data and it won’t generalize well. If I keep it too simple, then it might generalize well but it won’t detect all the underlying patterns in my training data. How do I know if my training data is generic enough? What issues can cause my machine learning model to be sub-optimal? Continue reading “Dissecting Bias vs. Variance Tradeoff In Machine Learning”
Autoencoders In Machine Learning
 When we talk about deep neural networks, we tend to focus on feature learning. Traditionally, in the field of machine learning, people use hand-crafted features. What this means is that we look at the data and build a feature vector which we think would be good and discriminative. Once we have that, we train a model to learn from it. But one of the biggest problems with this approach is that we don’t really know if it’s the best possible representation of the data. Ideally, we would want the machine to learn the features by itself, and then use it to build the machine learning model. Autoencoder is one such neural network which aims to learn how to build optimal feature vector for the given data. So how exactly does it work? How is it used in practice? Continue reading “Autoencoders In Machine Learning”
When we talk about deep neural networks, we tend to focus on feature learning. Traditionally, in the field of machine learning, people use hand-crafted features. What this means is that we look at the data and build a feature vector which we think would be good and discriminative. Once we have that, we train a model to learn from it. But one of the biggest problems with this approach is that we don’t really know if it’s the best possible representation of the data. Ideally, we would want the machine to learn the features by itself, and then use it to build the machine learning model. Autoencoder is one such neural network which aims to learn how to build optimal feature vector for the given data. So how exactly does it work? How is it used in practice? Continue reading “Autoencoders In Machine Learning”
What’s The Importance Of Hyperparameters In Machine Learning?
 Machine learning is becoming increasingly relevant in all walks of science and technology. In fact, it’s an integral part of many fields like computer vision, natural language processing, robotics, e-commerce, spam filtering, and so on. The list is potential applications is pretty huge! People working on machine learning tend to build models based on training data, in the hope that those models will perform well on unseen data. As we all know, every model has some parameters associated with it. We want our machine learning models to estimate these parameters from the training data. But as it turns out, there are a few parameters that cannot be estimated using this procedure. These parameters tend have a significant impact on the performance of your model. Now why is that? Where do these parameters come from? How do we deal with this? Continue reading “What’s The Importance Of Hyperparameters In Machine Learning?”
Machine learning is becoming increasingly relevant in all walks of science and technology. In fact, it’s an integral part of many fields like computer vision, natural language processing, robotics, e-commerce, spam filtering, and so on. The list is potential applications is pretty huge! People working on machine learning tend to build models based on training data, in the hope that those models will perform well on unseen data. As we all know, every model has some parameters associated with it. We want our machine learning models to estimate these parameters from the training data. But as it turns out, there are a few parameters that cannot be estimated using this procedure. These parameters tend have a significant impact on the performance of your model. Now why is that? Where do these parameters come from? How do we deal with this? Continue reading “What’s The Importance Of Hyperparameters In Machine Learning?”
What Is A Markov Chain?
 If you have studied probability theory, then you must have heard Markov’s name. When we study probability and statistics, we tend to deal with independent trials. What this means is that if you conduct an experiment a lot of times, we assume that the outcome of one trial doesn’t influence the outcome of the next trial. For example, let’s say you are tossing a coin. If you toss the coin 5 times, you are bound to get either heads or tails with equal probability. If the outcome of the first toss is heads, it doesn’t tell us anything about the next trial. But what if we are dealing with a situation where this assumption is not true? If we are dealing with something like estimating the weather, we cannot assume that today’s weather is not affected by what happened yesterday. If we go ahead with the independence assumption here, we are bound to get wrong results. How do we formulate this kind of model? Continue reading “What Is A Markov Chain?”
If you have studied probability theory, then you must have heard Markov’s name. When we study probability and statistics, we tend to deal with independent trials. What this means is that if you conduct an experiment a lot of times, we assume that the outcome of one trial doesn’t influence the outcome of the next trial. For example, let’s say you are tossing a coin. If you toss the coin 5 times, you are bound to get either heads or tails with equal probability. If the outcome of the first toss is heads, it doesn’t tell us anything about the next trial. But what if we are dealing with a situation where this assumption is not true? If we are dealing with something like estimating the weather, we cannot assume that today’s weather is not affected by what happened yesterday. If we go ahead with the independence assumption here, we are bound to get wrong results. How do we formulate this kind of model? Continue reading “What Is A Markov Chain?”
