 Machine learning is being used extensively in fields like computer vision, natural language processing, and data mining. In many modern applications that are being built, we usually derive a classifier or a model from an extremely large data set. The accuracy of the training algorithms is directly proportional to the amount of data we have. So most modern data sets often consist of a large number of examples, each of which is made up of many features. Having access to a lot of examples is very useful in extracting a good model from the data, but managing a large number of features is usually a burden to our algorithm. The thing is that some of these features may be irrelevant, so it’s important to make sure the final model doesn’t get affected by this. If the feature sets are complex, then our algorithm will be slowed down and it will be very difficult to find the global optimum. Given this situation, a good way to approach it would be to reduce the number of features we have. But if we do that in a careless manner, we might end up losing information. We want to reduce the number of features while retaining the maximum amount of information. Now what does it have to with manifold learning? Why do we care about reducing the dimensionality of our data? Continue reading “What Is Manifold Learning?”
Machine learning is being used extensively in fields like computer vision, natural language processing, and data mining. In many modern applications that are being built, we usually derive a classifier or a model from an extremely large data set. The accuracy of the training algorithms is directly proportional to the amount of data we have. So most modern data sets often consist of a large number of examples, each of which is made up of many features. Having access to a lot of examples is very useful in extracting a good model from the data, but managing a large number of features is usually a burden to our algorithm. The thing is that some of these features may be irrelevant, so it’s important to make sure the final model doesn’t get affected by this. If the feature sets are complex, then our algorithm will be slowed down and it will be very difficult to find the global optimum. Given this situation, a good way to approach it would be to reduce the number of features we have. But if we do that in a careless manner, we might end up losing information. We want to reduce the number of features while retaining the maximum amount of information. Now what does it have to with manifold learning? Why do we care about reducing the dimensionality of our data? Continue reading “What Is Manifold Learning?”
Category: Machine Learning
What Is AdaBoost?
 AdaBoost is short for Adaptive Boosting. It is basically a machine learning algorithm that is used as a classifier. Whenever you have a large amount of data and you want divide it into different categories, we need a good classification algorithm to do it. We usually use AdaBoost in conjunction with other learning algorithms to improve their performance. Hence the word ‘boosting’, as in it boosts other algorithms! Boosting is a general method for improving the accuracy of any given learning algorithm. So obviously, adaptive boosting refers to a boosting algorithm that can adjust itself to changing scenarios. But why do those algorithms need AdaBoost in the first place? Can AdaBoost function by itself? Continue reading “What Is AdaBoost?”
AdaBoost is short for Adaptive Boosting. It is basically a machine learning algorithm that is used as a classifier. Whenever you have a large amount of data and you want divide it into different categories, we need a good classification algorithm to do it. We usually use AdaBoost in conjunction with other learning algorithms to improve their performance. Hence the word ‘boosting’, as in it boosts other algorithms! Boosting is a general method for improving the accuracy of any given learning algorithm. So obviously, adaptive boosting refers to a boosting algorithm that can adjust itself to changing scenarios. But why do those algorithms need AdaBoost in the first place? Can AdaBoost function by itself? Continue reading “What Is AdaBoost?”
Why Would We Ever Use Blind Search?
 Over the last few decades, we have seen a lot of technologies come by and make a significant impact. Most of these technologies, if you have noticed, revolve around intelligent actions. Let’s say you are in the middle of a street and you want a cab. We can solve this problem in a couple of different ways depending on the level of intelligence we put into our solution. How can we design something that can make use of all the data and provide the best possible solution to the person in the middle of the street? We can say that intelligent action involves search in some way. Searching is needed in a variety of situations, so developing mathematically and computationally strong algorithms is an absolute must. In most of the real life situations, we don’t really know where to look or how a particular search is going to pan out. How do we formulate this? Continue reading “Why Would We Ever Use Blind Search?”
Over the last few decades, we have seen a lot of technologies come by and make a significant impact. Most of these technologies, if you have noticed, revolve around intelligent actions. Let’s say you are in the middle of a street and you want a cab. We can solve this problem in a couple of different ways depending on the level of intelligence we put into our solution. How can we design something that can make use of all the data and provide the best possible solution to the person in the middle of the street? We can say that intelligent action involves search in some way. Searching is needed in a variety of situations, so developing mathematically and computationally strong algorithms is an absolute must. In most of the real life situations, we don’t really know where to look or how a particular search is going to pan out. How do we formulate this? Continue reading “Why Would We Ever Use Blind Search?”
What Is Fuzzy Matching?
 This is a continuation of the previous blog post on fuzzy search. We use fuzzy matching algorithms in fuzzy search to come up with the search results. The strength of a fuzzy search algorithm heavily depends on the strength of the fuzzy matching algorithm that is being used. The concept of matching refers to an input being matched to a set of entries, or records, in your database to come up with the best possible match. We encounter this scenario very frequently in our everyday lives. Whenever you are looking up a word in the dictionary or when somebody is looking up your account during a customer service call, some form of matching is being used to get the answers. So how exactly does fuzzy matching work? What’s the big deal here? Continue reading “What Is Fuzzy Matching?”
This is a continuation of the previous blog post on fuzzy search. We use fuzzy matching algorithms in fuzzy search to come up with the search results. The strength of a fuzzy search algorithm heavily depends on the strength of the fuzzy matching algorithm that is being used. The concept of matching refers to an input being matched to a set of entries, or records, in your database to come up with the best possible match. We encounter this scenario very frequently in our everyday lives. Whenever you are looking up a word in the dictionary or when somebody is looking up your account during a customer service call, some form of matching is being used to get the answers. So how exactly does fuzzy matching work? What’s the big deal here? Continue reading “What Is Fuzzy Matching?”
What Is Fuzzy Search?
 The word “fuzzy” means something that is indistinct or vague, something that cannot be explained precisely. We all know what “search” means. That should give you a hint of what this blog post is about. Whenever you type something into the Google search engine, you will see that it always returns good results, even when you type the wrong spelling. How does it know what you meant? There are many different ways to misspell a word. How does it know exactly what word you have in mind? Continue reading “What Is Fuzzy Search?”
The word “fuzzy” means something that is indistinct or vague, something that cannot be explained precisely. We all know what “search” means. That should give you a hint of what this blog post is about. Whenever you type something into the Google search engine, you will see that it always returns good results, even when you type the wrong spelling. How does it know what you meant? There are many different ways to misspell a word. How does it know exactly what word you have in mind? Continue reading “What Is Fuzzy Search?”
Quantum Computing And Machine Learning
 Quantum Computing refers to the use of quantum mechanical phenomena to make computations. This field is making big strides in the last decade because it can actually help us solve some of the most challenging problems in the realm of computer science, particularly in machine learning and security. Machine learning is all about building better models of the world to make more accurate predictions and security is about safeguarding the things we have built. For example, if we want the machines to see things better, we need better models of how we process visual data. If we want to understand currency fluctuations, we need better models of how they change over time. If we want to create effective environmental policies, we need better models of what’s happening to our climate. So how can we use quantum computing to do these things? Continue reading “Quantum Computing And Machine Learning”
Quantum Computing refers to the use of quantum mechanical phenomena to make computations. This field is making big strides in the last decade because it can actually help us solve some of the most challenging problems in the realm of computer science, particularly in machine learning and security. Machine learning is all about building better models of the world to make more accurate predictions and security is about safeguarding the things we have built. For example, if we want the machines to see things better, we need better models of how we process visual data. If we want to understand currency fluctuations, we need better models of how they change over time. If we want to create effective environmental policies, we need better models of what’s happening to our climate. So how can we use quantum computing to do these things? Continue reading “Quantum Computing And Machine Learning”
What Is Random Walk?
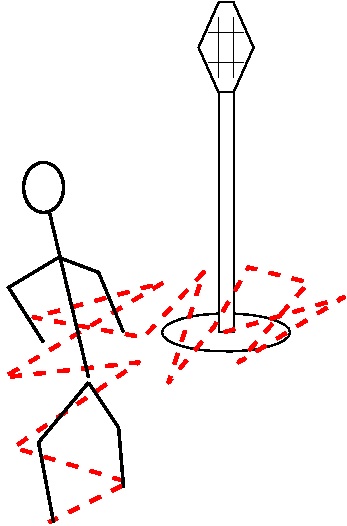 Consider the following situation. We have a drunkard who is clinging to a lamppost, and now he decides to start walking. He is in the middle of the street and the road runs from east to west. In his inebriated state, he is as likely to take a step towards the east as he is towards the west. It just means that there is a 50% chance that he will go in either direction. From each new position, he is again as likely to go east or west. Each of his steps are of the same length but in random direction. After having taken ‘n’ number of steps, he is to be found standing at some position on the street. This is what a random walk is. We can plot the position against the number of steps taken for any particular random walk. Now the question is, can we model his movement so that we can predict where he will be after taking ‘n’ steps? Continue reading “What Is Random Walk?”
Consider the following situation. We have a drunkard who is clinging to a lamppost, and now he decides to start walking. He is in the middle of the street and the road runs from east to west. In his inebriated state, he is as likely to take a step towards the east as he is towards the west. It just means that there is a 50% chance that he will go in either direction. From each new position, he is again as likely to go east or west. Each of his steps are of the same length but in random direction. After having taken ‘n’ number of steps, he is to be found standing at some position on the street. This is what a random walk is. We can plot the position against the number of steps taken for any particular random walk. Now the question is, can we model his movement so that we can predict where he will be after taking ‘n’ steps? Continue reading “What Is Random Walk?”
Gaussian Mixture Models
 Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this? Continue reading “Gaussian Mixture Models”
Let’s say you have a lot of data and you want to estimate the underlying statistical model. Wait a minute, why on earth would I care about that? Well, if you estimate the model, then you can analyze unknown data that is not under our control. Some of the common examples would be weather estimation, facial expressions analysis, speech recognition, share prices, etc. Coming back to the estimation problem, the simplest thing to do would be compute the mean and variance of this data, hence getting the governing distribution. But what if there are multiple subgroups in this data? As in, how do we detect the presence of subpopulations within an overall population? Even though the data points belong to the overall data, we need to understand the different modes inside the data. How do we go about doing this? Continue reading “Gaussian Mixture Models”
Overfitting In Machine Learning
 Let’s say you are given a small set of data points. These data points can take any form like weight distribution of people, location of people who buy your products, types of smartphones, etc. Now your job is to estimate the underlying model. As in, if an unknown point comes in, you should to be able to fit it into your model. Typical supervised learning stuff! But the problem is that you have very few datapoints to begin with. So how do we accurately estimate that model? Should you really tighten your model to satisfy every single point you have? Continue reading “Overfitting In Machine Learning”
Let’s say you are given a small set of data points. These data points can take any form like weight distribution of people, location of people who buy your products, types of smartphones, etc. Now your job is to estimate the underlying model. As in, if an unknown point comes in, you should to be able to fit it into your model. Typical supervised learning stuff! But the problem is that you have very few datapoints to begin with. So how do we accurately estimate that model? Should you really tighten your model to satisfy every single point you have? Continue reading “Overfitting In Machine Learning”
What Is K-Means Clustering?
 Let’s say you get a whole bunch of data samples and you want to do some analysis about the underlying structure of those samples. You know that they can be categorized into certain groups, but you are not exactly sure what those categories are. For example, you get the data associated with shopping behavior of consumers. You want to understand what products are more popular, what kind of consumers buy these products, what time of the year do consumers buy more, etc. In order to divide this data into subgroups, we need to know what those groups should be in the first place. In our case, we don’t! This becomes increasingly difficult as you get more samples, often ranging in hundreds of thousands. So how do we analyze this data? How do we make the machine automatically learn the underlying structure and categorize accordingly? Continue reading “What Is K-Means Clustering?”
Let’s say you get a whole bunch of data samples and you want to do some analysis about the underlying structure of those samples. You know that they can be categorized into certain groups, but you are not exactly sure what those categories are. For example, you get the data associated with shopping behavior of consumers. You want to understand what products are more popular, what kind of consumers buy these products, what time of the year do consumers buy more, etc. In order to divide this data into subgroups, we need to know what those groups should be in the first place. In our case, we don’t! This becomes increasingly difficult as you get more samples, often ranging in hundreds of thousands. So how do we analyze this data? How do we make the machine automatically learn the underlying structure and categorize accordingly? Continue reading “What Is K-Means Clustering?”
