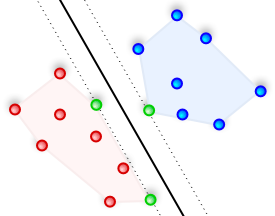
 Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
Support Vector Machines are machine learning models that are used to classify data. Let’s say you want to build a system that can automatically identify if the input image contains a given object. For ease of understanding, let’s limit the discussion to three different types of objects i.e. chair, laptop, and refrigerator. To build this, we need to collect images of chairs, laptops, and refrigerators so that our system can “learn” what these objects look like. Once it learns that, it can tell us whether an unknown image contains a chair or a laptop or a refrigerator. SVMs are great at this task! Even though it can predict the output, wouldn’t it be nice if we knew how confident it is about the prediction? This would really help us in designing a robust system. So how do we compute these confidence measures? Continue reading “How To Compute Confidence Measure For SVM Classifiers”
Tag: Artificial Intelligence
Dissecting Bias vs. Variance Tradeoff In Machine Learning
 I was recently working on a machine learning problem when I stumbled upon an interesting question. I wanted to build a machine learning model using a labeled dataset that can classify an unknown image. It’s a classic supervised learning problem! I was not exactly sure how the model would turn out, so I had to experiment with a bunch of things. If I fine tune the machine learning model too much, then it will be very specific to my training data and it won’t generalize well. If I keep it too simple, then it might generalize well but it won’t detect all the underlying patterns in my training data. How do I know if my training data is generic enough? What issues can cause my machine learning model to be sub-optimal? Continue reading “Dissecting Bias vs. Variance Tradeoff In Machine Learning”
I was recently working on a machine learning problem when I stumbled upon an interesting question. I wanted to build a machine learning model using a labeled dataset that can classify an unknown image. It’s a classic supervised learning problem! I was not exactly sure how the model would turn out, so I had to experiment with a bunch of things. If I fine tune the machine learning model too much, then it will be very specific to my training data and it won’t generalize well. If I keep it too simple, then it might generalize well but it won’t detect all the underlying patterns in my training data. How do I know if my training data is generic enough? What issues can cause my machine learning model to be sub-optimal? Continue reading “Dissecting Bias vs. Variance Tradeoff In Machine Learning”
Autoencoders In Machine Learning
 When we talk about deep neural networks, we tend to focus on feature learning. Traditionally, in the field of machine learning, people use hand-crafted features. What this means is that we look at the data and build a feature vector which we think would be good and discriminative. Once we have that, we train a model to learn from it. But one of the biggest problems with this approach is that we don’t really know if it’s the best possible representation of the data. Ideally, we would want the machine to learn the features by itself, and then use it to build the machine learning model. Autoencoder is one such neural network which aims to learn how to build optimal feature vector for the given data. So how exactly does it work? How is it used in practice? Continue reading “Autoencoders In Machine Learning”
When we talk about deep neural networks, we tend to focus on feature learning. Traditionally, in the field of machine learning, people use hand-crafted features. What this means is that we look at the data and build a feature vector which we think would be good and discriminative. Once we have that, we train a model to learn from it. But one of the biggest problems with this approach is that we don’t really know if it’s the best possible representation of the data. Ideally, we would want the machine to learn the features by itself, and then use it to build the machine learning model. Autoencoder is one such neural network which aims to learn how to build optimal feature vector for the given data. So how exactly does it work? How is it used in practice? Continue reading “Autoencoders In Machine Learning”
What’s The Importance Of Hyperparameters In Machine Learning?
 Machine learning is becoming increasingly relevant in all walks of science and technology. In fact, it’s an integral part of many fields like computer vision, natural language processing, robotics, e-commerce, spam filtering, and so on. The list is potential applications is pretty huge! People working on machine learning tend to build models based on training data, in the hope that those models will perform well on unseen data. As we all know, every model has some parameters associated with it. We want our machine learning models to estimate these parameters from the training data. But as it turns out, there are a few parameters that cannot be estimated using this procedure. These parameters tend have a significant impact on the performance of your model. Now why is that? Where do these parameters come from? How do we deal with this? Continue reading “What’s The Importance Of Hyperparameters In Machine Learning?”
Machine learning is becoming increasingly relevant in all walks of science and technology. In fact, it’s an integral part of many fields like computer vision, natural language processing, robotics, e-commerce, spam filtering, and so on. The list is potential applications is pretty huge! People working on machine learning tend to build models based on training data, in the hope that those models will perform well on unseen data. As we all know, every model has some parameters associated with it. We want our machine learning models to estimate these parameters from the training data. But as it turns out, there are a few parameters that cannot be estimated using this procedure. These parameters tend have a significant impact on the performance of your model. Now why is that? Where do these parameters come from? How do we deal with this? Continue reading “What’s The Importance Of Hyperparameters In Machine Learning?”
Image Classification Using Fisher Vectors
 This is a continuation of my previous blog post on image classification and the bag of words (BoW) model. If you already know how BoW works, then you will feel right at home. If you need a refresher, you can read the blog post here. In our previous post, we discussed how BoW works, and how we construct the codebook. An interesting thing to note is that we don’t consider how things are ordered as such. A given image is treated as a combination of codewords regardless of where they are located with respect to each other. If we want to improve the performance of BoW, we can definitely increase the size of the vocabulary. If we have more codewords, we can describe a given image better. But what if we don’t want to do that? Is there a more efficient method that can be used? Continue reading “Image Classification Using Fisher Vectors”
This is a continuation of my previous blog post on image classification and the bag of words (BoW) model. If you already know how BoW works, then you will feel right at home. If you need a refresher, you can read the blog post here. In our previous post, we discussed how BoW works, and how we construct the codebook. An interesting thing to note is that we don’t consider how things are ordered as such. A given image is treated as a combination of codewords regardless of where they are located with respect to each other. If we want to improve the performance of BoW, we can definitely increase the size of the vocabulary. If we have more codewords, we can describe a given image better. But what if we don’t want to do that? Is there a more efficient method that can be used? Continue reading “Image Classification Using Fisher Vectors”
Image Classification Using Bag-Of-Words Model
 Image classification is one of the classical problems in computer vision. Basically, the goal is to determine whether or not the given image contains a particular thing like an object or a person. Humans tend to classify images effortlessly, but machines seem to have a hard time doing this. Computer Vision has achieved some success in the case of specific problems, like detecting faces in an image. But it has still not satisfactorily solved the problem for the general case where we have random objects in different positions and orientations. Bag-of-words (BoW) model is one of the most popular approaches in this field, and many modern approaches are based on top of this. So what exactly is it? Continue reading “Image Classification Using Bag-Of-Words Model”
Image classification is one of the classical problems in computer vision. Basically, the goal is to determine whether or not the given image contains a particular thing like an object or a person. Humans tend to classify images effortlessly, but machines seem to have a hard time doing this. Computer Vision has achieved some success in the case of specific problems, like detecting faces in an image. But it has still not satisfactorily solved the problem for the general case where we have random objects in different positions and orientations. Bag-of-words (BoW) model is one of the most popular approaches in this field, and many modern approaches are based on top of this. So what exactly is it? Continue reading “Image Classification Using Bag-Of-Words Model”
Recognizing Shapes Using Point Distribution Models
 In the field of computer vision, we often come across situations where we need to recognize the shapes of different objects. Not only that, we also need our machines to understand the shapes so that we can identify them even if we encounter them in different forms. Humans are really good at these things. We somehow make a mental note about these shapes and create a mapping in our brain. But if somebody asks you to write a formula or a function to identify it, we cannot come up with a precise set of rules. In fact, the whole field of computer vision is based on chasing this hold grail. In this blog post, we will discuss a particular model which is used to identify different shapes. Continue reading “Recognizing Shapes Using Point Distribution Models”
In the field of computer vision, we often come across situations where we need to recognize the shapes of different objects. Not only that, we also need our machines to understand the shapes so that we can identify them even if we encounter them in different forms. Humans are really good at these things. We somehow make a mental note about these shapes and create a mapping in our brain. But if somebody asks you to write a formula or a function to identify it, we cannot come up with a precise set of rules. In fact, the whole field of computer vision is based on chasing this hold grail. In this blog post, we will discuss a particular model which is used to identify different shapes. Continue reading “Recognizing Shapes Using Point Distribution Models”
What Is AdaBoost?
 AdaBoost is short for Adaptive Boosting. It is basically a machine learning algorithm that is used as a classifier. Whenever you have a large amount of data and you want divide it into different categories, we need a good classification algorithm to do it. We usually use AdaBoost in conjunction with other learning algorithms to improve their performance. Hence the word ‘boosting’, as in it boosts other algorithms! Boosting is a general method for improving the accuracy of any given learning algorithm. So obviously, adaptive boosting refers to a boosting algorithm that can adjust itself to changing scenarios. But why do those algorithms need AdaBoost in the first place? Can AdaBoost function by itself? Continue reading “What Is AdaBoost?”
AdaBoost is short for Adaptive Boosting. It is basically a machine learning algorithm that is used as a classifier. Whenever you have a large amount of data and you want divide it into different categories, we need a good classification algorithm to do it. We usually use AdaBoost in conjunction with other learning algorithms to improve their performance. Hence the word ‘boosting’, as in it boosts other algorithms! Boosting is a general method for improving the accuracy of any given learning algorithm. So obviously, adaptive boosting refers to a boosting algorithm that can adjust itself to changing scenarios. But why do those algorithms need AdaBoost in the first place? Can AdaBoost function by itself? Continue reading “What Is AdaBoost?”
What Is Metaprogramming? – Part 2/2
 This is a continuation of my previous blog post on metaprogramming. In the previous post, we saw why we need metaprogramming. In this post, we will see what exactly this whole metaprogramming is all about. In the world of programming, the basic problem is that any general-purpose programming language is that it has its own limitations. If the language doesn’t have a metaprogramming model that is as pleasant and expressive as the language itself, then it will eventually frustrate the user. Nobody can design the perfect language, we get that! The people who manage these languages don’t allow the users to extend the language in generic ways. Not a bad thing altogether! This is done because a lot of people end up extending it in too many different ways and it becomes one big potpourri of nastiness. Coming back to the topic at hand, how exactly do we understand metaprogramming? Continue reading “What Is Metaprogramming? – Part 2/2”
This is a continuation of my previous blog post on metaprogramming. In the previous post, we saw why we need metaprogramming. In this post, we will see what exactly this whole metaprogramming is all about. In the world of programming, the basic problem is that any general-purpose programming language is that it has its own limitations. If the language doesn’t have a metaprogramming model that is as pleasant and expressive as the language itself, then it will eventually frustrate the user. Nobody can design the perfect language, we get that! The people who manage these languages don’t allow the users to extend the language in generic ways. Not a bad thing altogether! This is done because a lot of people end up extending it in too many different ways and it becomes one big potpourri of nastiness. Coming back to the topic at hand, how exactly do we understand metaprogramming? Continue reading “What Is Metaprogramming? – Part 2/2”
What Is Metaprogramming? – Part 1/2
 You know how people talk about creating machines that can create more machines by themselves? Well, we already have machines that can create other machines. The concept of metaprogramming is just the technical side of it. Metaprogramming is the process of writing programs that can create other programs. It is one of the most underused programming techniques. The good thing is that it allows programmers to minimize the number of lines of code to express a solution, or it gives programs greater flexibility to efficiently handle new situations without recompilation. If it’s so good, then why isn’t it used everywhere? Why do we need it? Before we jump into the details of metaprogramming, let’s understand why we would consider it in the first place. Continue reading “What Is Metaprogramming? – Part 1/2”
You know how people talk about creating machines that can create more machines by themselves? Well, we already have machines that can create other machines. The concept of metaprogramming is just the technical side of it. Metaprogramming is the process of writing programs that can create other programs. It is one of the most underused programming techniques. The good thing is that it allows programmers to minimize the number of lines of code to express a solution, or it gives programs greater flexibility to efficiently handle new situations without recompilation. If it’s so good, then why isn’t it used everywhere? Why do we need it? Before we jump into the details of metaprogramming, let’s understand why we would consider it in the first place. Continue reading “What Is Metaprogramming? – Part 1/2”
