 In machine learning, we use a lot of supervised learning models to analyze data and recognize patterns. If we consider the basic problem of binary classification, a machine learning algorithm takes a set of input data and predicts which of two possible classes a particular input belongs to. Kernel-classifiers comprise a powerful class of non-linear decision functions for binary classification. These classifiers are very useful when you cannot draw a straight line to separate two classes. The support vector machine (SVM) is a good example of a learning algorithm for kernel classifiers. It looks at all the boundaries and picks the one with the largest margin. It is widely used in many different fields and it has a very strong mathematical foundation. Now it is being claimed that Bayes Point Machine (BPM) is an improvement over SVM. Pretty bold claim! So what exactly is a BPM? How is it better than SVM? Continue reading “Bayes Point Machines”
In machine learning, we use a lot of supervised learning models to analyze data and recognize patterns. If we consider the basic problem of binary classification, a machine learning algorithm takes a set of input data and predicts which of two possible classes a particular input belongs to. Kernel-classifiers comprise a powerful class of non-linear decision functions for binary classification. These classifiers are very useful when you cannot draw a straight line to separate two classes. The support vector machine (SVM) is a good example of a learning algorithm for kernel classifiers. It looks at all the boundaries and picks the one with the largest margin. It is widely used in many different fields and it has a very strong mathematical foundation. Now it is being claimed that Bayes Point Machine (BPM) is an improvement over SVM. Pretty bold claim! So what exactly is a BPM? How is it better than SVM? Continue reading “Bayes Point Machines”
Tag: Pattern Recognition
What Are Conditional Random Fields?
 This is a continuation of my previous blog post. In that post, we discussed about why we need conditional random fields in the first place. We have graphical models in machine learning that are widely used to solve many different problems. But Conditional Random Fields (CRFs) address a critical problem faced by these graphical models. A popular example for graphical models is Hidden Markov Models (HMMs). HMMs have gained a lot of popularity in recent years due to their robustness and accuracy. They are used in computer vision, speech recognition and other time-series related data analysis. CRFs outperform HMMs in many different tasks. How is that? What are these CRFs and how are they formulated? Continue reading “What Are Conditional Random Fields?”
This is a continuation of my previous blog post. In that post, we discussed about why we need conditional random fields in the first place. We have graphical models in machine learning that are widely used to solve many different problems. But Conditional Random Fields (CRFs) address a critical problem faced by these graphical models. A popular example for graphical models is Hidden Markov Models (HMMs). HMMs have gained a lot of popularity in recent years due to their robustness and accuracy. They are used in computer vision, speech recognition and other time-series related data analysis. CRFs outperform HMMs in many different tasks. How is that? What are these CRFs and how are they formulated? Continue reading “What Are Conditional Random Fields?”
Why Do We Need Conditional Random Fields?
 This is a two-part discussion. In this blog post, we will discuss the need for conditional random fields. In the next one, we will discuss what exactly they are and how do we use them. The task of assigning labels to a set of observation sequences arises in many fields, including computer vision, bioinformatics, computational linguistics and speech recognition. For example, consider the natural language processing task of labeling the words in a sentence with their corresponding part-of-speech tags. In this task, each word is labeled with a tag indicating its appropriate part of speech, resulting in annotated text. To give another example, consider the task of labeling a video with the mental state of a person based on the observed behavior. You have to analyze the facial expressions of the user and determine if the user is happy, angry, sad etc. We often wish to predict a large number of variables that depend on each other as well as on other observed variables. How to achieve these tasks? What model should we use? Continue reading “Why Do We Need Conditional Random Fields?”
This is a two-part discussion. In this blog post, we will discuss the need for conditional random fields. In the next one, we will discuss what exactly they are and how do we use them. The task of assigning labels to a set of observation sequences arises in many fields, including computer vision, bioinformatics, computational linguistics and speech recognition. For example, consider the natural language processing task of labeling the words in a sentence with their corresponding part-of-speech tags. In this task, each word is labeled with a tag indicating its appropriate part of speech, resulting in annotated text. To give another example, consider the task of labeling a video with the mental state of a person based on the observed behavior. You have to analyze the facial expressions of the user and determine if the user is happy, angry, sad etc. We often wish to predict a large number of variables that depend on each other as well as on other observed variables. How to achieve these tasks? What model should we use? Continue reading “Why Do We Need Conditional Random Fields?”
Derandomization Of RANSAC
 Let’s say you are a clothes designer and you want to design a pair of jeans. Since you are new to all this, you go out and collect a bunch of measurements from people to see how to design your jeans as far as sizing is concerned. One aspect of this project would be to see how the height of a person relates to the size of the jeans you are designing. From the measurements you took from those people, you notice a certain pattern that relates height of a person to the overall size of the jeans. Now you generalize this pattern and say that for a given height, a particular size is recommended. To deduce the pattern, you just took a bunch of points and drew a line through them so that it is close to all those points. Pretty simple right! What if there are a few points that are way off from all the other points? Would you consider them while deducing your pattern? You will probably discard them because they are outliers. This was a small sample set, so you could notice these outliers manually. What if there were a million points? Continue reading “Derandomization Of RANSAC”
Let’s say you are a clothes designer and you want to design a pair of jeans. Since you are new to all this, you go out and collect a bunch of measurements from people to see how to design your jeans as far as sizing is concerned. One aspect of this project would be to see how the height of a person relates to the size of the jeans you are designing. From the measurements you took from those people, you notice a certain pattern that relates height of a person to the overall size of the jeans. Now you generalize this pattern and say that for a given height, a particular size is recommended. To deduce the pattern, you just took a bunch of points and drew a line through them so that it is close to all those points. Pretty simple right! What if there are a few points that are way off from all the other points? Would you consider them while deducing your pattern? You will probably discard them because they are outliers. This was a small sample set, so you could notice these outliers manually. What if there were a million points? Continue reading “Derandomization Of RANSAC”
Expectation Maximization
 Probabilistic models are commonly used to model various forms of data, including physical, biological, seismic, etc. Much of their popularity can be attributed to the existence of efficient and robust procedures for learning parameters from observations. Often, however, the only data available for training a probabilistic model are incomplete. Missing values can occur which will not be sufficient to get the model. For example, in medical diagnosis, patient histories generally include results from a limited battery of tests. In gene expression clustering, incomplete data arise from the intentional omission of gene-to-cluster assignments in the probabilistic model. If we use regular techniques to estimate the underlying model, then we will get a wrong estimate. What do we do in these situations? Continue reading “Expectation Maximization”
Probabilistic models are commonly used to model various forms of data, including physical, biological, seismic, etc. Much of their popularity can be attributed to the existence of efficient and robust procedures for learning parameters from observations. Often, however, the only data available for training a probabilistic model are incomplete. Missing values can occur which will not be sufficient to get the model. For example, in medical diagnosis, patient histories generally include results from a limited battery of tests. In gene expression clustering, incomplete data arise from the intentional omission of gene-to-cluster assignments in the probabilistic model. If we use regular techniques to estimate the underlying model, then we will get a wrong estimate. What do we do in these situations? Continue reading “Expectation Maximization”
The Genesis Of Genetic Algorithms
 Let’s say you have a function and you want to optimize it. In real life, this function can take many forms like choosing the right set of features for your car while keep the price low, picking the best possible apartment considering all the different factors like location, rent, closeness to stores etc, making a business plan, and many other things. In fact, we continuously use optimization in our everyday life without even realizing it. The interesting thing to note is that we don’t get the most optimal answer every time. We just look around for a while and stop when we get a good enough answer. More often than not, these answers are sub-optimal, mostly depending on the initial point we chose. So how do we get to the best answer? There might be billions of options, do we need check all of them to get to this global optimum? Continue reading “The Genesis Of Genetic Algorithms”
Let’s say you have a function and you want to optimize it. In real life, this function can take many forms like choosing the right set of features for your car while keep the price low, picking the best possible apartment considering all the different factors like location, rent, closeness to stores etc, making a business plan, and many other things. In fact, we continuously use optimization in our everyday life without even realizing it. The interesting thing to note is that we don’t get the most optimal answer every time. We just look around for a while and stop when we get a good enough answer. More often than not, these answers are sub-optimal, mostly depending on the initial point we chose. So how do we get to the best answer? There might be billions of options, do we need check all of them to get to this global optimum? Continue reading “The Genesis Of Genetic Algorithms”
Bayesian Classifier
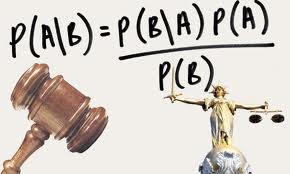 In machine learning, classification is the process of identifying the category of an unknown input based on the set of categories we already have. A classifier, as the name suggests, classifies things into multiple categories. It is used in various real life situations like face detection, image search, fingerprint recognition, etc. Some of the tasks are really simple and a machine can identify the class with absolute certainty. A common example would be to determine if a given number is even or odd. Pretty simple right! But most of the real life problems are not this simple and there is absolutely no way a machine can identify it with absolute certainty. For example, object recognition, weather prediction, handwriting analysis etc. So how do machines deal with these problems? What approach can be used here? Continue reading “Bayesian Classifier”
In machine learning, classification is the process of identifying the category of an unknown input based on the set of categories we already have. A classifier, as the name suggests, classifies things into multiple categories. It is used in various real life situations like face detection, image search, fingerprint recognition, etc. Some of the tasks are really simple and a machine can identify the class with absolute certainty. A common example would be to determine if a given number is even or odd. Pretty simple right! But most of the real life problems are not this simple and there is absolutely no way a machine can identify it with absolute certainty. For example, object recognition, weather prediction, handwriting analysis etc. So how do machines deal with these problems? What approach can be used here? Continue reading “Bayesian Classifier”
What Does Backpropagation Mean?
 People started working on artificial intelligence back in the late ’60s. After they came up with the concept of perceptron, this field looked very promising. But as the years passed by, no significant development took place even after making several attempts from multiple directions! As people were beginning to lose hope, backpropagation came into picture and breathed new life into this field. Backpropagation was the result of pioneering work by mathematicians and computer scientists, which eventually led to a successful revival of artificial intelligence! So what exactly is backpropagation? How is it used in real life? Continue reading “What Does Backpropagation Mean?”
People started working on artificial intelligence back in the late ’60s. After they came up with the concept of perceptron, this field looked very promising. But as the years passed by, no significant development took place even after making several attempts from multiple directions! As people were beginning to lose hope, backpropagation came into picture and breathed new life into this field. Backpropagation was the result of pioneering work by mathematicians and computer scientists, which eventually led to a successful revival of artificial intelligence! So what exactly is backpropagation? How is it used in real life? Continue reading “What Does Backpropagation Mean?”
Perceiving The Perceptron
 If you are hearing the word “perceptron” for the first time, it sounds a lot like a futuristic robot which can perceive things right? Well, that’s not exactly what it means! Perceptron is a machine learning algorithm for supervised classification. It is one of the very first algorithms to be formulated in the field of artificial intelligence. When it first came out, it was very promising. But over the following years, the performance didn’t exactly reach the expectations. It was studied for many years and the theory was modified and extended in a lot of ways. Now, it has become an integral part in the field of artificial neural networks. So what exactly is a perceptron? Where do we use it in real life? Continue reading “Perceiving The Perceptron”
If you are hearing the word “perceptron” for the first time, it sounds a lot like a futuristic robot which can perceive things right? Well, that’s not exactly what it means! Perceptron is a machine learning algorithm for supervised classification. It is one of the very first algorithms to be formulated in the field of artificial intelligence. When it first came out, it was very promising. But over the following years, the performance didn’t exactly reach the expectations. It was studied for many years and the theory was modified and extended in a lot of ways. Now, it has become an integral part in the field of artificial neural networks. So what exactly is a perceptron? Where do we use it in real life? Continue reading “Perceiving The Perceptron”
Principal Component Analysis
 Principal Component Analysis (PCA) is one of most useful tools in the field of pattern recognition. Let’s say you are making a list of people and collecting information about their physical attributes. Some of the more common attributes include height, weight, chest, waist and biceps. If you store 5 attributes per person, it is equivalent to storing a 5-dimensional feature vector. If you generalize it for ‘n’ different attributes, you are constructing an n-dimensional feature vector. Now you may want to analyze this data and cluster people into different categories based on these attributes. PCA comes into picture when have a set of datapoints which are multidimensional feature vectors and the dimensionality is high. If you want to analyze the patterns in our earlier example, it’s quite simple because it’s just a 5-dimensional feature vector. In real-life systems, the dimensionality is really high (often in hundreds or thousands) and it becomes very complex and time-consuming to analyze such data. What should we do now? Continue reading “Principal Component Analysis”
Principal Component Analysis (PCA) is one of most useful tools in the field of pattern recognition. Let’s say you are making a list of people and collecting information about their physical attributes. Some of the more common attributes include height, weight, chest, waist and biceps. If you store 5 attributes per person, it is equivalent to storing a 5-dimensional feature vector. If you generalize it for ‘n’ different attributes, you are constructing an n-dimensional feature vector. Now you may want to analyze this data and cluster people into different categories based on these attributes. PCA comes into picture when have a set of datapoints which are multidimensional feature vectors and the dimensionality is high. If you want to analyze the patterns in our earlier example, it’s quite simple because it’s just a 5-dimensional feature vector. In real-life systems, the dimensionality is really high (often in hundreds or thousands) and it becomes very complex and time-consuming to analyze such data. What should we do now? Continue reading “Principal Component Analysis”
